欢迎大家向我们投稿,会同步到微信公众号,投稿方式见这里。
博客
- 0.14 版本更新介绍
- Zig comptime 棒极了
- 在 zig 中实现类型安全的有限状态机
- zoop 实现原理分析
- 5: 社区新闻
- Zig 分配器的应用
- HashMap 原理介绍下篇
- HashMap 原理介绍上篇
- Zig 标准库中的实现接口的惯用法与模式
- build.zig.zon 中的依赖项哈希值
- 通过 Zig,学习 C++ 元编程
- 如何发布 Zig 应用程序
- zig 构建系统解析 - 第三部分
- zig 构建系统解析 - 第二部分
- zig 构建系统解析 - 第一部分
- Zig 多版本管理
- Zig音频之MIDI —— 源码解读
- Bog GC Design
- Bog GC 设计 -- 概念篇
- 欢迎 Zig 爱好者向本网站供稿
0.14 版本更新介绍
https://ziglang.org/download/0.14.0/release-notes.html
发布概览
Zig 0.14.0 版本是经过 9 个月的工作,由 251 位不同的贡献者 完成,包含 3467 个提交 的成果。该版本专注于提升 健壮性、最优性 和 可重用性,并通过 Zig 软件基金会 (Zig Software Foundation) 资助开发。
核心主题与重要更新
- 提升编译速度与开发效率:
- 版本说明强调了两个重要的长期投资:增量编译 (Incremental Compilation) 和 快速 x86 后端 (fast x86 Backend)。
- 这两项投资的核心目标是 “reducing edit/compile/debug cycle latency”(减少编辑/编译/调试循环延迟)。
- 增量编译 功能在本次发布中可以通过 -fincremental 标志选择启用,但目前尚未完全成熟。它在配合文件系统监控时表现良好,尤其是在仅检查编译错误时能显著提升反馈速度。
- 引用:$ zig build -Dno-bin -fincremental –watch (展示了在大型代码库中快速获得编译错误反馈的示例)。
- 目前不兼容 usingnamespace,建议用户尽量避免使用。
- x86 后端 在行为测试中表现出色,已经通过了 98% 的测试用例,编译速度显着快于 LLVM 后端,并且支持更好的调试器。它有望在下一个发布周期成为调试模式下的默认后端。可以通过 -fno-llvm 或 use_llvm = false 启用。
- 引用:The x86 backend is now passing 1884/1923 (98%) of the behavior test suite compared to the LLVM backend.
- 增强目标平台支持 (Target Support):
- 这是一个主要主题,Zig 的跨平台编译能力得到了极大扩展。
- 版本说明详细列出了不同目标平台在语言特性、标准库、代码生成、链接器、调试信息、libc 和 CI 测试等方面的支持级别,采用分层系统 (Tier System) 进行分类(Tier 1 为最高级别)。
- 引用:A major theme in this Zig release is improved target support; the list of targets that Zig can correctly cross-compile to and run on has been greatly expanded.
- 对 arm/thumb, mips/mips64, powerpc/powerpc64, riscv32/riscv64, 或 s390x 等目标平台的工具链问题、标准库支持缺失和崩溃问题有了显著改进。
- 更新了目标三元组 (Target Triple Changes) 的命名和支持,以更准确地反映不同平台(如 Windows、Linux 使用 musl libc)的 ABI 和特性。
- 重要的语言特性变化 (Language Changes):
- 标记 switch (Labeled Switch): 允许 switch 语句拥有标签并被 continue 语句指向,从而实现更清晰的状态机实现。关键动机在于生成优化后的代码,特别是通过不同的分支指令帮助 CPU 进行更准确的分支预测,提升性能。
- 引用:Zig 0.14.0 implements an accepted proposal which allows switch statements to be labeled, and to be targeted by continue statements.
- 引用:This language construct is designed to generate code which aids the CPU in predicting branches between cases of the switch, allowing for increased performance in hot loops…
- 更新 Zig 的 tokenizer 利用此特性带来了 13% 的性能提升。
- 声明字面量 (Decl Literals): 扩展了 .foo 语法,不仅可以引用枚举成员,还可以引用目标类型上的任何声明 (const/var/fn)。这使得初始化结构体字段和调用初始化函数更加简洁和安全,特别是避免了无效的默认字段值问题。
- 引用:Zig 0.14.0 extends the “enum literal” syntax (.foo) to provide a new feature, known as “decl literals”.
- 许多现有使用字段默认值的地方可能更适合使用 default 或 empty 等声明来处理,以确保数据不变性。
- 字段和声明不能共享名称 (Fields and Declarations Cannot Share Names): 引入了容器类型(struct, union, enum, opaque)的字段和声明不能同名的限制,解决了歧义问题并便于文档生成。
- 引用:Zig 0.14.0 introduces a restriction that container types (struct , union , enum and opaque ) cannot have fields and declarations ( const / var / fn ) with the same names.
- @splat 支持数组 (@splat Supports Arrays): 扩展了 @splat 内置函数,使其可以应用于数组和哨兵终止数组,方便用常量值初始化数组。
- 引用:Zig 0.14.0 expands the @splat builtin to apply not only to vectors, but to arrays.
- 全局变量可以相互引用地址 (Global Variables can be Initialized with Address of Each Other): 允许全局变量在初始化时相互引用地址。
- @export 操作数现在是指针 (@export Operand is Now a Pointer): @export 内置函数现在接受一个指针作为操作数,使其用法更清晰和一致,通常只需在旧用法前添加 &。
- 新的 @branchHint 内置函数,取代 @setCold (New @branchHint Builtin, Replacing @setCold): 引入 @branchHint 内置函数,允许开发者向优化器提示分支的可能性,有 .none, .likely, .unlikely, .cold, .unpredictable 等选项。这取代了旧的 @setCold。
- 引用:Zig 0.14.0 introduces a mechanism to communicate this information: the new @branchHint(comptime hint: std.builtin.BranchHint) builtin.
- @branchHint 必须是其所在块或函数的第一个语句。
- 移除 @fenceStoreLoad Barriers: 移除 @fence(.StoreLoad),其功能现在可以通过使用 SeqCst 或 Acquire/Release 原子操作来实现。
- Packed Struct Equality 和 Packed Struct Atomics: 允许直接对 Packed Struct 进行相等性比较和原子操作,不再需要 @bitCast 到底层整数类型。
- @ptrCast 允许改变切片长度 (@ptrCast Allows Changing Slice Length): #22706
- 移除匿名结构体类型,统一元组 (Remove Anonymous Struct Types, Unify Tuples): 重构匿名结构体字面量和元组的工作方式,使其使用“普通”结构体类型和基于 AST 节点及结构体的等价性。
- Calling Convention 增强和 @setAlignStack 被取代 (Calling Convention Enhancements and @setAlignStack Replaced): std.builtin.CallingConvention 现在是一个标记联合,包含更多目标平台特定的调用约定,并允许通过 CommonOptions 设置栈对齐等选项。.c 调用约定现在是一个声明,可以通过 callconv(.c) 使用 Decl Literals 访问。@setAlignStack 被移除,其功能现在通过调用约定的选项实现。
- *std.builtin.Type 字段重命名和简化 (std.builtin.Type Fields Renamed and Simplify Usage Of ?const anyopaque): std.builtin.Type 联合体的字段名称改为小写,并增加了对 default_value_ptr 和 sentinel_ptr 字段的 helper 方法,以简化使用。
- 不允许非标量哨兵类型 (Non-Scalar Sentinel Types Disallowed): 哨兵值现在只能是支持 == 操作符的标量类型。
- @FieldType 内置函数 (@FieldType builtin): 新增 @FieldType 内置函数,用于获取给定类型和字段名称的字段类型,取代了 std.meta.FieldType 函数。
- @src 获得 Module 字段 (@src Gains Module Field): std.builtin.SourceLocation 结构体新增 module 字段。
- @memcpy 规则调整 ( @memcpy Rules Adjusted): langspec 定义调整,源和目标元素类型必须内存可强制转换,从而确保是原始复制操作。对 comptime @memcpy 增加了别名检查和更高效的实现。
- 禁止不安全的内存强制转换 (Unsafe In-Memory Coercions Disallowed): #22243
- callconv, align, addrspace, linksection 不能引用函数参数 (#22264callconv, align, addrspace, linksection Cannot Reference Function Arguments): #22264
- 函数调用的分支配额规则调整 (Branch Quota Rules Adjusted for Function Calls): #22414
- 标准库改进 (Standard Library):
- DebugAllocator 和 SmpAllocator: 重写了 GeneralPurposeAllocator 并更名为 DebugAllocator,提高了调试模式下的性能。新增了 SmpAllocator,一个针对 ReleaseFast 模式和多线程优化的单例分配器,性能可与 glibc 媲美。
- Allocator API 变化 (remap): std.mem.Allocator.VTable 新增了 remap 函数,允许在可能的情况下进行无需 memcpy 的内存重映射。resize 语义不变。Allocator.VTable 函数现在使用 std.mem.Alignment 类型。
- ZON 解析和序列化 (ZON Parsing and Serialization): std.zon.parse 提供运行时解析 ZON 到 Zig 结构体的功能,std.zon.stringify 提供运行时序列化功能。
- 运行时页面大小 (Runtime Page Size): 移除了编译时已知的 std.mem.page_size,代之以编译时已知的 std.heap.page_size_min 和 std.heap.page_size_max。std.heap.pageSize() 提供运行时实际页面大小。解决了在 Apple 新硬件上运行 Linux 的支持问题。
- Panic 接口 (#22594Panic Interface): #22594
- Transport Layer Security (std.crypto.tls): #21872
- process.Child.collectOutput API 变化 (#21872process.Child.collectOutput API Changed): API 签名改变,现在将 allocator 作为第一个参数传入。
- LLVM Builder API: LLVM bitcode builder API 移至 std.zig.llvm,方便第三方项目复用。
- 拥抱“非管理”风格容器 (Embracing “Unmanaged”-Style Containers): 大部分带有内置 allocator 的标准库容器(如 std.ArrayList, std.ArrayHashMap)已被弃用,推荐使用“非管理”风格容器(如 std.ArrayListUnmanaged, std.ArrayHashMapUnmanaged),并在需要时显式传递 allocator。
- std.c 重组 (std.c Reorganization): 重组了 std.c,使其结构更清晰,并改变了对不存在符号的处理方式(从 @compileError 改为 void 或 {}),移除了标准库中最后一个 usingnamespace 的使用点。
- 弃用列表 (List of Deprecations): 列出了大量被弃用或重命名的标准库函数和类型。
- Binary Search: #20927
- std.hash_map 获得 rehash 方法 (#20927std.hash_map gains a rehash method): 为解决 HashMap 移除元素后的性能下降问题新增了 rehash 方法(Array Hash Map 没有此问题)。此方法预计在未来不再需要时会被删除。
- 构建系统升级 (Build System):
- 基于现有模块创建 Artifacts (Creating Artifacts from Existing Modules): 修改了构建系统 API,允许从现有的 std.Build.Module 对象创建 Compile 步骤,使模块图的定义更清晰,组件复用更容易。旧的 API 用法已被弃用。
- 引用:Zig 0.14.0 modifies the build system APIs for creating Compile steps, allowing them to be created from existing std.Build.Module objects.
- 允许包按名称暴露任意 LazyPath (Allow Packages to Expose Arbitrary LazyPaths by Name): 新增 std.Build.addNamedLazyPath 和 std.Build.Module.namedLazyPath 方法,允许依赖包按名称暴露生成的 LazyPath 给其依赖者使用。
- addLibrary 函数: 新增 addLibrary 函数,取代 addSharedLibrary 和 addStaticLibrary,使得在 build.zig 中更容易切换链接模式,并与 linkLibrary 名称更匹配。
- 文件系统监控 (File System Watching): #22105
- 新包哈希格式 (New Package Hash Format): 引入新的包哈希格式,包含 32 位 id 和 32 位校验和,用于在去中心化生态系统中唯一标识包。当 fork 项目时,如果上游仍维护,应该重新生成 fingerprint。
- WriteFile Step, RemoveDir Step, Fmt Step: 新增或改进了这些构建步骤。
- Breakings: 多个 installHeader 和 installHeadersDirectory 相关函数签名改变,现在接受 LazyPath。生成的 -femit-h 头文件不再默认发出。
- 编译器和链接器改进 (Compiler and Linker):
- 多线程后端支持 (Multithreaded Backend Support): 部分编译器后端(如 x86 后端)支持在单独线程中运行代码生成,显著提升了编译速度。
- LLVM 19: 升级到 LLVM 19.1.7。
- 链接器输入文件解析移至前端 (Move Input File Parsing to the Frontend): 将 GNU ld 脚本处理移至前端,以便在编译开始时了解所有链接器输入,实现编译和链接同时进行。为了避免对所有 .so 文件进行文件系统访问,新增了 -fallow-so-scripts 命令行标志,允许用户选择启用对 .so 脚本的支持。
- 引用:Moves GNU ld script processing to the frontend to join the relevant library lookup logic, making the libraries within subject to the same search criteria as all the other libraries.
- 集成模糊测试器 (Fuzzer):
- Zig 0.14.0 集成了一个模糊测试器,目前处于 alpha 状态。通过 –fuzz 命令行选项启用。
- 可以针对包含 std.testing.fuzz 的单元测试二进制文件进行进程内模糊测试。
- 提供了 Web UI (http://127.0.0.1:38239/) 显示实时代码覆盖率。
- Bug 修复与 Toolchain 更新 (Bug Fixes and Toolchain):
- 关闭了 416 个 bug 报告。但版本说明坦承 “This Release Contains Bugs”,并指出在 1.0.0 版本达到 Tier 1 支持时会增加 bug 策略。
- UBSan Runtime: Debug 模式下默认启用 UBSan 运行时库,为 C 代码的未定义行为提供更详细的恐慌信息和堆栈跟踪。可以通过 -fno-ubsan-rt 和 -fubsan-rt 控制。
- compiler_rt: 包含了优化的 memcpy 实现。
- musl 1.2.5: 捆绑的 musl 更新并应用了 CVE 修复和目标平台特定补丁。不再捆绑 musl 的 memcpy 文件,而是使用 Zig 的优化实现。
- glibc 2.41: 支持 glibc 2.40 和 2.41 交叉编译,修复了多个与 glibc 相关的问题。
- Linux 6.13.4 Headers, Darwin libSystem 15.1, MinGW-w64, wasi-libc: 更新了捆绑的操作系统头文件和 libc 版本。捆绑了 winpthreads 库。
社区贡献与资助:
- 版本说明详细感谢了 251 位 为本次发布做出贡献的开发者。
- 特别感谢了通过经常性捐赠支持 Zig 的个人和组织赞助商,强调了开源社区驱动的重要性。
路线图展望:
- 版本说明中穿插提到了未来的一些计划,例如提升增量编译的成熟度、使 x86 后端成为调试模式下的默认选项、改进 ZON 导入,以及未来容器和哈希地图的改进。
- 最终目标是达到 1.0.0 版本,届时 Tier 1 支持将包含 bug 政策。
关于 Zig 0.14.0 版本的常见问题解答
Zig 0.14.0 版本的主要更新和亮点是什么?
Zig 0.14.0 版本是长达 9 个月开发工作和 3467 次提交的成果,主要亮点包括:显著增强了对多种目标平台的支持,包括 arm/thumb、mips/mips64、powerpc/powerpc64、riscv32/riscv64 和 s390x 等,许多之前存在工具链问题、标准库支持缺失或崩溃的情况现在应该可以正常工作了。此外,该版本在构建系统方面进行了大量升级,并对语言进行了多项重要改进,例如引入了 Labeled Switch 和 Decl Literals 等新特性。为了缩短编辑/编译/调试周期,版本还迈向了两个长期投资目标:增量编译和快速 x86 后端。
Zig 如何对不同目标平台的开发支持进行分级?
Zig 使用四层系统来对不同目标平台的支持级别进行分类,其中 Tier 1 是最高级别:
- Tier 1: 所有非实验性语言特性都能正常工作。编译器能够独立生成目标平台的机器代码,功能与 LLVM 相当。即使在交叉编译时,该目标平台也有可用的 libc。
- Tier 2: 标准库的跨平台抽象在该目标平台上有实现。该目标平台具备调试信息能力,可以在断言失败和崩溃时生成堆栈跟踪。CI 机器在每次 master 分支提交时都会自动构建和测试该目标平台。
- Tier 3: 编译器可以依赖外部后端(如 LLVM)为该目标平台生成机器代码。链接器可以为该目标平台生成目标文件、库和可执行文件。
- Tier 4: 编译器可以依赖外部后端(如 LLVM)为该目标平台生成汇编源代码。如果 LLVM 将此目标平台视为实验性,则需要从源代码构建 LLVM 和 Zig 才能使用它。
什么是 Labeled Switch,它有什么优势?
Labeled Switch 是 Zig 0.14.0 中引入的一项语言特性,允许 switch 语句被标记,并作为 continue 语句的目标。continue :label value 语句会用 value 替换原始的 switch 表达式操作数,并重新评估 switch。尽管在语义上类似于循环中的 switch,但 Labeled Switch 的关键优势在于其代码生成特性。它可以生成帮助 CPU 更准确预测分支的代码,从而提高热循环中的性能,特别是在处理指令分派、评估有限状态自动机 (FSA) 或执行类似基于 case 的评估时。这有助于 branch predictor 更准确地预测控制流。
Decl Literals 是什么,它解决了哪些问题?
Decl Literals 是 Zig 0.14.0 扩展 “enum literal” 语法 (.foo) 而引入的新特性。现在,一个枚举字面量 .foo 不仅可以引用枚举变体,还可以使用 Result Location Semantics 引用目标类型上的任何声明(const/var/fn)。这在初始化结构体字段时特别有用,可以避免重复指定类型,并有助于避免 Faulty Default Field Values 的问题,确保数据不变量不会因覆盖单个字段而受到破坏。它也支持直接调用函数来初始化值。
Zig 0.14.0 版本在内存分配器方面有哪些值得关注的变化?
该版本对内存分配器进行了多项改进:
- DebugAllocator: GeneralPurposeAllocator 已被重写并更名为 DebugAllocator,以解决其依赖于编译时已知的页面大小的问题,并提升性能。
- SmpAllocator: 引入了一个新的分配器,专为 ReleaseFast 优化模式和多线程环境设计。它是一个单例,使用全局状态,每个线程拥有独立的空闲列表,并通过原子操作处理线程资源回收,即使线程退出也能恢复数据。其性能与 glibc 相当。
- Allocator API Changes (remap): std.mem.Allocator.VTable 引入了一个新的 remap 函数,允许尝试扩展或收缩内存并可能重新定位,如果无法在不执行内部 memcpy 的情况下完成,则返回 null,提示调用者自行处理复制。同时,resize 函数保持不变。Allocator.VTable 中的所有函数现在使用 std.mem.Alignment 类型代替 u8,增加了类型安全。
- Runtime Page Size: 移除了编译时已知的 std.mem.page_size,代之以编译时已知的页面大小上下界 std.heap.page_size_min 和 std.heap.page_size_max。运行时获取页面大小可以使用 std.heap.pageSize(),它会优先使用编译时已知的值,否则在运行时查询操作系统并缓存结果。这修复了对 Asahi Linux 等新硬件上运行 Linux 的支持。
Zig 0.14.0 版本如何改进构建系统,特别是处理模块和依赖关系?
Zig 0.14.0 版本在构建系统方面有多项重要改进:
- Creating Artifacts from Existing Modules: 修改了构建系统 API,允许从现有的 std.Build.Module 对象创建 Compile 步骤。这使得模块图的定义更加清晰,并且可以更容易地重用图中的组件。
- Allow Packages to Expose Arbitrary LazyPaths by Name: 引入了 std.Build.Step.addNamedLazyPath 方法,允许包暴露命名的 LazyPath,例如生成的源代码文件,供依赖包使用。
- New Package Hash Format: 引入了新的包哈希格式,包括 name、version 和 fingerprint 字段。fingerprint 是一个重要的概念,用于全局唯一标识包,即使在去中心化的生态系统中也能准确识别更新版本。
- addLibrary Function: 引入 addLibrary 函数作为 addSharedLibrary 和 addStaticLibrary 的替代,允许在 build.zig 中更容易地切换链接模式,并与 linkLibrary 函数名称保持一致。
- Import ZON: ZON 文件现在可以在编译时通过 @import(“foo.zon”) 导入,前提是结果类型已知。
Zig 0.14.0 版本在编译器后端和编译速度方面有哪些进展?
该版本在编译器后端和编译速度方面取得了进展:
- Multithreaded Backend Support: 部分编译器后端,如 x86 Backend,现在支持在单独的线程中运行代码生成,这显著提高了编译速度。
- Incremental Compilation: 引入了增量编译特性,可以通过 -fincremental 标志启用。尽管尚未默认启用,但结合文件系统监听,可以显著缩短修改代码后的重新分析时间,提供快速的编译错误反馈。
- x86 Backend: x86 后端在行为测试套件中的通过率已接近 LLVM 后端,并且在开发时通常比 LLVM 后端提供更快的编译速度和更好的调试器支持。虽然尚未默认选中,但鼓励用户尝试使用 -fno-llvm 或在构建脚本中设置 use_llvm = false 来启用。
Zig 0.14.0 版本在工具链和运行时方面有哪些值得注意的更新?
该版本在工具链和运行时方面也有多项更新:
- UBSan Runtime: Zig 现在为 UBSan 提供了运行时库,在 Debug 模式下默认启用,可以在 C 代码触发未定义行为时提供详细的错误信息和堆栈跟踪。
- LLVM 19: Zig 已升级到 LLVM 19.1.7 版本。
- musl 1.2.5: 更新了捆绑的 musl 版本,并应用了安全补丁和目标平台特定补丁。
- glibc 2.41: 支持 cross-compiling glibc 2.40 和 2.41 版本,并修复了多个问题,提高了与 glibc 的兼容性。
- Linux 6.13.4 Headers: 包含了 Linux 内核头文件版本 6.13.4。
- Darwin libSystem 15.1: 包含了 Xcode SDK 版本 15.1 的 Darwin libSystem 符号。
- MinGW-w64: 更新了捆绑的 MinGW-w64 版本,并捆绑了 winpthreads 库,支持 cross-compiling 到 thumb-windows-gnu。
- wasi-libc: 更新了捆绑的 wasi-libc 版本。
- Optimized memcpy: 提供了优化的 memcpy 实现,不再捆绑 musl 的 memcpy 文件。
- Integrated Fuzzer: 集成了 alpha 质量的 fuzzer,可以通过 –fuzz CLI 选项使用,并提供一个 fuzzer Web UI 显示实时代码覆盖率。
总结
Zig 0.14.0 版本是向 1.0.0 版本迈进的重要一步,在性能优化(尤其是编译速度)、跨平台支持、语言特性和标准库方面都带来了显著改进。增量编译和快速 x86 后端是关键的长期投资,旨在提升开发者体验。新语言特性如 Labeled Switch 和 Decl Literals 提供了更强大和安全的编程模式。标准库的重组和容器的调整反映了社区的使用模式和最佳实践。构建系统也获得了重要升级,使模块管理和依赖处理更加灵活。尽管仍存在已知 bug,但 Zig 社区在本次发布中展示了活跃的开发和持续的进步。
Zig comptime 棒极了
译注:原文中的代码块是交互式,翻译时并没有移植。另外,由于 comptime 本身即是关键概念,并且下文的意思更侧重于 Zig comptime 的特性,故下文大多使用 comptime 代替编译时概念。
引子
编程通过自动化地处理数据极大地提升了生产力。而元编程则让我们可以像处理数据一样处理代码,以此将编程的力量反向作用于编程自身。而在底层编程中,我想元编程可能带来最大的优势,因为那些高级概念必须得精确映射到某些低级操作。然而,除了函数式编程语言外,我一直觉得各编程语言对元编程的实现并不理想。因此,当我看到 Zig 把元编程列为一个主要特性时,我提起了很大的兴趣。
说实话,刚开始使用 Zig 的 comptime 时,我的体验相当糟糕。那些概念对我而言很陌生,而想要实现预期的效果也很困难。不过后来,当我转换了思路,一切都迎刃而解了,由此,我突然就喜欢上了它。现在,为了帮助你更快地走上这条探索之路,下面我将介绍六种不同的“视角”来理解 comptime。每个视角都从不同的角度,帮助你将已有的编程知识应用到 Zig 中。
这并不是一本完整涵盖了 comptime 的所有所需知识的详细指南。相反,它更侧重于提供多种策略,从不同视角帮助你全面地理解该如何以 comptime 的角度思考问题。
为了明确起见,所有示例都是有效的 Zig 代码,但示例中的转换只是概念性的,它们并不是 Zig 实际的实现方式。
视角0: 忽略它
我说我喜欢这个特性,却又立刻叫你忽略它,这确实有点怪。但我认为此处正是 Zig comptime 威力所体现的地方,所以我将从这里出发。Zig Zen 中的第三条是“倾向于阅读代码,而不是编写代码。”确实,能够轻松地阅读代码在各种情况下都很重要,因为它是建立概念理解的基础,而这种理解也是调试或修改代码所必需的。
元编程很容易让人陷入“只写代码”的境地。如果你在使用基于宏的元编程或代码生成器,那么代码就会变成两种版本:源代码和展开后的代码。这个额外的间接层使得从阅读到调试代码的整个过程都变得更加困难。当你要改变程序的行为时,你不仅需要确定生成的代码应该是什么样的,还需要弄清楚该如何通过元编程来生成这些代码。
但在 Zig 中,这些额外的开销是完全不需要的。你可以简单地忽略代码在不同时间执行这一隐形的前提条件,而在概念上直接将运行时和编译时的区别忽略掉再来理解那些代码。为了演示这一点,让我们一步一步来看两个不同的代码示例。第一个是普通的运行时代码,第二个则是利用了 comptime 的代码。
普通的运行时代码
| |
点击“下一步”逐步执行程序,观察状态的变化。这个例子很简单:对一组数字求和。现在我们来做些奇怪的事:对一个结构体的字段求和。虽然这个例子有些牵强,但却能够很好地展示这一概念。
基于 comptime 的代码
| |
与数组求和的例子相比,这个 comptime 示例引入的新东西几乎是微不足道的。这正是 comptime 的重点!这段代码的可执行文件效率和你在 C 中为结构体类型手写一个求和函数一样高效,而它却看起来像是你在使用支持运行时反射的语言编写的。虽然这不是 Zig 实际的工作方式,但这也不完全是一个纯粹的理论练习:Zig 核心团队正在开发一个调试器,允许你像这个例子一样逐步执行混合了编译时和运行时的代码。
Zig 中有很多基于 comptime 且远远不止这样简单的类型反射,但你只需要阅读那些代码、完全无需深入了解其中有关 comptime 的细节就可以理解它们在干什么。当然,如果你想使用 comptime 编写代码,则不能仅仅止步于此,让我们继续深入。
视角1: 泛型
泛型在 Zig 中并不是一个特定的功能。相反,Zig 中的仅仅一小部分的 comptime 特性就可以提供用来处理你进行泛型编程所需的一切。这种视角虽然不能让你完全理解 comptime,但它确实为你提供了一个入口点,借此,你可以完成基于元编程的许多任务。
要使一个类型成为泛型,只需将其定义包裹在一个接受类型并返回类型的函数中。(译注:由于 Zig 中类型是一等公民,所以面向类型的编程是合法且常见的)
| |
泛型函数也可以如此实现。
| |
当然,也可以通过使用特殊类型 anytype 来推断参数的类型,而这通常在参数的类型对函数签名的其余部分没有影响时使用。(译注:此时要限制 a, b, c 的类型相同,所以此处不用 anytype )
视角2:编译时运行的标准代码
这是一个古老的故事: 增加一种自动执行命令的方法。当然,你还需要变量。 哦,还有条件。 拜托,能给我循环吗?这些看似合理的需求,最终导致这些自动化命令变得越来越复杂,甚至演变成一个完整的宏语言。 但 Zig 不同, 在运行时、编译时,甚至是构建系统中都使用了相同的语言。
考虑经典的 Fizz Buzz。
| |
确实很简单。但是,每当讨论如何优化 Fizz Buzz 算法时,人们总是忽略一个事实:标准的 Fizz Buzz 问题只需要输出前100个数字的结果。既然输出是固定的,那为什么不直接预先计算出答案,然后输出呢?(由此,我时常认为那些有关优化讨论有些滑稽的。) 我们可以使用相同的 Fizz Buzz 函数来实现这一点。
| |
这里的 comptime 关键字表示它后面的代码块将在编译期间运行。此外,该代码块被标记为“init”,以便整个块可以通过之后的 break 语句产出一个值。
我们一开始用一个 null_writer 来计算写入的字节数(但会丢弃实际写入的字节),以确定总长度。然后再根据该长度创建 full_fizzbuzz 数组来保存实际数据。
仅对关键部分进行计时,预计算版本的运行速度约快 9 倍。当然,这个例子过于简单,以至于总执行时间受到很多其他因素的影响,但你不难借此明白这其中 comptime 对于性能优化的意味。
comptime 和运行时之间有一些小的区别。比如,只有 comptime 可以访问类型为 comptime_int、comptime_float 或 type 的变量。此外,一些函数只有 comptime 参数,这使它们仅限于编译时环境。相对的,只有运行时才能进行系统调用和那些依赖系统调用的函数。如果你的代码不使用这些特性,那么它在编译时和运行时中的表现将是一样的。
视角3:程序特化
译者注:程序特化(Partial Evaluation)是一种编译优化技术,主要是:在编译期预先计算部分表达式或代码路径,以减少运行时计算开销,提前生成更具体的代码实现。
现在我们要进入有趣的部分。
译注:请参考下面的代码和代码后的解释理解这句话。
代码求值的一种方式是将输入替换为其运行时值,然后反复将第一个表达式替换为求值形式,直到表达式为基本元素。这在计算机科学理论上下文中很常见,在某些函数式语言中也是如此。作为后续示例的铺垫,我们将使用数组求和来展示这个过程:
| |
程序特化是一种可以向函数传递部分(但不一定是全部)参数的技术。 在这种情况下,可以对只使用已知值的表达式进行替换。 这样就产生了一个新函数,它只接受仍然未知的参数。 comtime 可以看作是在编译过程中进行的部分求值。 再看一下 sum 结构的例子,我们就会发现:
| |
上面的示例是我们手动展开后的示例,但这项工作是由 Zig 的 comptime 完成的。这使得我们可以直接独立而完整地编写出我们要实现的功能,而不需要添加"当你改变 MyStruct 的字段时,记得更新 sum 函数"这样的由于依赖于 MyStruct 具体字段而预防功能失效的注释。
基于 comptime 的版本在 MyStruct 的任何字段变更时都可以正确地自动处理。
视角4:Comptime 求值,运行时代码生成
这与程序特化(Partial Evaluation)非常相似。这里有两个版本的代码,输入(编译前)和输出(编译后)。输入代码由编译器运行。如果一个语句在编译时是可知的,它就会被直接求值。但是如果一个语句需要某些运行时的值,那么这个语句就会被添加到输出代码中。
让我们以数组求和为例来说明这个过程:
输入这一段代码:
| |
生成出的代码:
| |
这实际上是最接近 Zig 编译器处理 comptime 的方式。他们的主要区别在于 Zig 首先解析你的代码的语法,并将其转换为虚拟机的字节码。这个虚拟机的运行方式就是 comptime 的实现方式。这个虚拟机将估量它能处理的所有内容,并为需要运行时处理的内容生成新的字节码(稍后将其转换为机器码)。具有运行时输入的条件语句,如 if 语句,会直接输出两条路径。
自然,这样做的后果是死代码永远不会被语义分析。也就是说,一个无效的函数并不总是会在实际被使用之前产出相应的编译错误。(对此你可能需要适应一段时间)然而,这也使得编译更加高效(译注:部分地弥补了 Zig 暂不支持增量编译的缺陷),并允许更自然的外观条件编译,这里没有 #ifdef (译注:谢天谢地~)!
值得注意的是, comptime 在 Zig 的设计中是个很基本的设计, 所有的 Zig 代码都通过这个虚拟机运行,包括没有明显使用 comptime 的函数。 即使是简单的类型名称,如函数参数,实际上也是在 comptime 中评估类型变量的表达式。 这就是上面泛型示例的工作原理。 这也意味着您可以酌情使用更复杂的表达式来计算类型。
这样做的另一个后果是,Zig 代码的静态分析要比大多数静态类型语言复杂得多,因为编译器需要运行很大一部分才能确定所有类型。 因此,在 Zig 工具链跟上之前,代码自动补全等编辑工具并不总是能很好地发挥作用。
视角5:直接生成代码(Textual Code Generation)
我在文章开头感叹元编程难度。然而,即使在 Zig 中,它仍然是一个强大的工具,在解决某些问题方面也占有一席之地。如果您熟悉这种元编程方法,对 Zig comptime 提供的功能可能会觉得有些残缺。比如, 怎么在写一段代码在运行时能够生成新代码?
但等等,上一个例子不就是这样吗? 如果你以正确的方式看待问题,写代码的代码和混合运行时代码之间存在着潜在的等价关系。
下有两例。第一个是一个元编程的示例,第二个是我们熟悉的 comptime 示例。这两个版本的代码有着相同的逻辑。
| |
注意这里有两个转换:
- 在生成器中直接运行的代码是 comptime 的一部分
- 在生成器执行后输出的代码,成为运行时的一部分
我喜欢这个示例的另一点是,它展示了在 Zig 中使用类型信息作为输入来生成代码是多么简单。这个例子略过了类型名称和字段名称信息的来源。如果你使用其他形式的输入,比如 Zig 提供了 @embedFile,你可以像平常一样解析它。
回到泛型的例子,有一些值得强调的细微之处:
| |
以上 struct 字段的生成体现了上述两种转换方式,并且将两者混合在了一行中。 字段的类型表达式由生成器/运行时完成,而字段本身则作为运行时代码使用的定义。
在 comptime 下,引用类型名称的方式更加直接,可以直接使用函数,而不必将文本拼接成一个在代码生成中保持一致的名称。
这种观点有一个例外。 您可以创建字段名称在编译时就已确定的类型,但这样做需要调用一个内置函数,该函数包含一个字段定义列表。 因此,您无法在这些类型上定义方法等声明。 在实践中,这并不会限制代码的表达能力,但确实限制了你可以向其他代码公开哪些类型的 API。
与本节相关的是文本宏,如 C 语言中的文本宏。你可以做的大多数正常事情都可以在 comptime 中完成,尽管它们很少采用类似的形式。 不过,文本宏并不能做所有允许做的事情。 例如,你不能决定不喜欢某个 Zig 关键字,然后让宏代替你自己的关键字。 我认为这是一个正确的决定,尽管对于那些习惯了这种能力的人来说,这是一个艰难的过渡。 此外,Zig 参考了半个世纪以来的程序员在这方面的探索,所以它的选择要理智得多。
结论
在阅读 Zig 代码以理解代码行为时,考虑 comptime 并不是必要的。而当编写 comptime 代码时,我通常会将其视为程序特化(Partial Evaluation)的一种形式。然而,如果你知道如何使用不同的元编程方法解决问题,你很可能有能力将其翻译成 comptime 形式。
元编程中直接生成代码的方法的存在,就是我全力支持 Zig 风格的 comptime 元编程的原因。尽管,直接生成代码是几乎是最强大的,但是,在阅读和调试时忽略 comptime 的特性的元编程方法确是最简单的。正因如此,我给本文取名为《Zig comptime 棒极了》。
进一步阅读
Zig 并非一个仅仅依赖 comptime 这一特性的语言。你可以在官方网站上了解更多关于 Zig 的信息。
在这篇文章中,我多次使用相同的例子来展示不同的转换方式(代码->编译时和运行时),以简化展示的过程。这样做的缺点是,尽管谈论了很多,但实际上我并没有展示太多相关的内容。而语言参考文档详细介绍了编译时的具体特性。
如果您想看到更多示例,我建议您阅读一些 Zig 的标准库代码。以下是一些供有兴趣者参考的链接:
- std.debug.print 是一个强大的泛型函数。许多语言在运行时解析它们的格式字符串,并很可能为字符串格式添加了一些特殊的效验器,以尽早捕获错误。而在 Zig 中,格式字符串是在编译时解析的,这样不仅生成了高效的最终代码,还在编译时完成了所有的校验。
- ArrayList 是一个实现相对简单但功能齐全的泛型容器。
Zig 的函数可以具有几种不同的返回类型。但是,这并不是依赖于编译器中的某些魔法的操作,而只是典型的 comptime 的应用。
如果您希望就本篇文章向我提出意见或更正,请发送电子邮件至 blogcomments@scottredig.com。 译者注:如果觉得翻译有问题,请提 PR 改正:https://github.com/zigcc/zigcc.github.io
在 zig 中实现类型安全的有限状态机
1. 简单介绍类型化有限状态机的优势
1.1 介绍有限状态机
有限状态机(FSM,以下简称状态机)是程序中很常见的设计模式。
它包含两个主要的概念状态和消息。状态机程序整体上的行为就是不断地产生消息,处理消息。
而状态主要是在代码层面帮助人们理解消息的产生和处理。
1.2 typed-fsm-zig
typed-fsm-zig 是一个利用 zig 类型系统加一些编程规范实现的一个库,用于实现类型安全的有限状态机。
它具有以下两点优势:
类型安全,极大方便代码的编写,修改和重构 手写状态机在实际代码中有很大的心智负担,对于它的修改和重构更是如噩梦一样。
typed-fsm-zig 在类型上跟踪状态机的变化,使消息的定义,产生,处理都和状态相关联,从而让类型系统帮我们检查这个过程中是否存在状态错误。
在编写,修改和重构的时候,任何状态的错误都会产生编译错误,而这些编译错误能帮助我们快速找到问题,解决问题。
PS:推荐在 zls 中打开保存时检查,这样你几乎能得到一个交互式的状态机开发环境。
简单高效,无任何代码生成,能方便与现有逻辑整合
typed-fsm-zig 是一种编程的思想,掌握这种思想就能方便的使用它。
在实际的使用中没有任何的代码生成,除了一处隐式的约束要求之外,没有任何其它的控制,开发者完全掌握状态机,因此你可以方便的将它和你现有的代码结合起来。
2. 例子:修改 ATM 状态机的状态
这里我将以一个 ATM 状态机(以下简称 ATM)的例子来展示 typed-fsm-zig 和 zig 的类型系统如何帮助我快速修改 ATM 的状态。
为了简单性,这里我不展示构建 ATM 这个例子的过程,感兴趣的可以在这里看到代码。
2.1 介绍 ATM 状态机
ATM 代表自动取款机,因此它的代码的逻辑就是模拟自动取款机的一些行为:插入银行卡,输入 pin,检查 pin,取钱,修改 pin。
它的状态机整体如下:
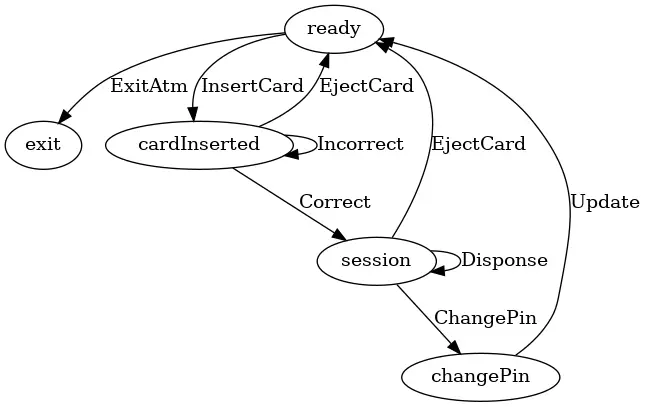
图中椭圆形表示状态,箭头表示消息。 它包含五种状态:exit, ready, cardInserted, session, changePin。
同时它也包含一堆的消息,每个消息都包含了系统状态的转化。 比如消息 InsertCard 代表将 ATM 的状态从 ready 转化到 cardInserted,这代表用户插入卡。
消息 Incorrect 代表将 ATM 的状态从 cardInserted 转化到 cardInserted, 这代表了一种循环,表示用户输错了 pin,但是可以再次尝试输入 pin,当然我们要求最多可以尝试三次。
整个程序效果如下:
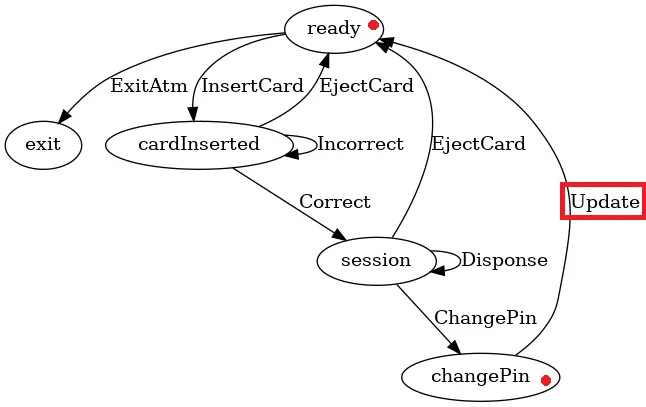
这里注意消息 Update,它代表更新 pin,同时将状态转从 changePin 换到 ready。
实际的表现就是在 changePin 的界面中我们修改 pin,然后点击 Change 按钮触发 Update 消息,修改 pin,并返回到 ready 界面。
接下来的文章中我将修改 Update 的行为,并展示在这个过程中类型系统如何帮助我快速调整代码。
2.2 修改 Update 消息
实际的消息 Update 定义代码如下
| |
这里的.ready 就代表了处理完 Update 消息后就会进入 ready 状态。
我们修改这里,把它变成.cardInserted,这代表了我们要求更新完 pin 之后进入 cardInserted 界面重新输入新的 pin,这看着是个合理的要求。
新的状态图如下:
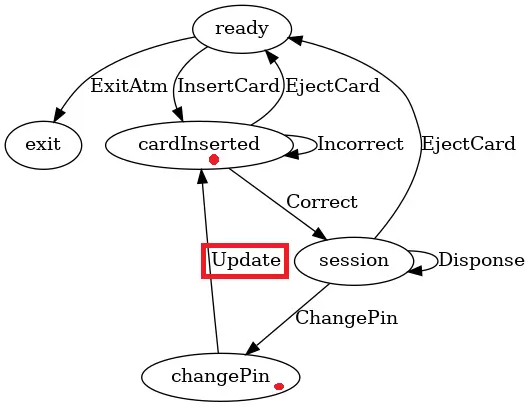
这时如果我重新编译代码,那么类型系统就会产生下面的错误:
| |
它告诉我们在 301 行存在类型不匹配。因为之前的状态是 ready 所以使用 readyHandler。
当我们把 Update 的状态修改为 cardInserted 时,它与 readyHandler 类型不匹配,应该将它修改为 cardInsertedHandler。
修改之后的代码如下:
| |
在这里类型系统精确的告诉了我们需要修改的地方,以及原因。修改完成后程序即能正确运行。
2.3 移除 changePin 状态
这一节中我们尝试移除 changePin 状态,看看类型系统会给我们什么反馈。 如果移除 changePin,新的状态图如下:
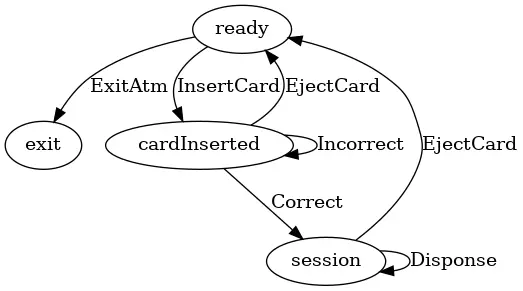
重新编译项目,将获得类型系统的反馈
类型系统的反馈首先是:
| |
因为 changePin 状态已经被移除,因此消息 ChangePin(它代表了从 session 进入 changePin 状态)也不应该再存在了,我们移除它再重新编译。
新的反馈如下:
| |
我们移除 ChangePin 消息,因此也将它从消息产生的地方移除,继续重新编译。
新的反馈如下:
| |
因为消息 ChangePin 已经不在了,也应将它从消息处理的地方移除,继续重新编译。
这一次不再有编译错误产生,我们搞定了一个新的程序,它不再包含 changePin 的逻辑。
在这个过程中类型系统帮助我们找到问题和原因。这非常酷!!!
2.4 总结
以上是一个简单的例子,展示了 typed-fsm-zig 对于提升状态机编程体验的巨大效果。
展示类型系统如何帮助我们指示错误的地方,把复杂的状态机修改变成一种愉快的编程经历。
还有些没有讲到的优势如下:
- 状态的分离,后端 handler 处理业务的状态变化,前端渲染和消息生成不改变状态。
- 消息生成受到类型的限制和状态相关,这样避免错误消息的产生。
这些优势对于复杂业务有很大的帮助。
接下来我将介绍 typed-fsm-zig 的原理和实现。
3. 原理与实现
最开始的版本是typed-fsm,由使用 haskell 实现,它实现了完整类型安全的有限状态机。
typed-fsm 基于Mcbride Indexed Monad:
| |
这是一种特殊的 monad,能在类型上为不确定状态建模。
而在 zig 实现中移除了对 Monad 语义的需求,保留了在类型上追踪状态的能力。
所以它不具备完整的类型安全的能力,需要依靠编程规范来约束代码的行为。我认为这样的取舍是值得的,它的类型安全性在 zig 中完全够用。
以下是一个原型例子,它包含了 typed-fsm-zig 的核心想法。看不懂不需要担心,接下来我将详细解释这些代码。
| |
首先是 Witness,它是一个类型上的证据,用来跟踪类型上状态的变化。
感兴趣的可以看一下,看懂这些要求你了解 GADT,上面提到的 Mcbirde Indexed Monad 本质就是在 GADT 类型上的 monad。
在这里的 Winess 三个参数分别表示:
- T 表示状态机的类型,
- end 表示终止时的状态,
- start 表示当前的状态。
它还有两个函数:
- getMsg 表示从外部获取消息的函数
- terminal 表示终止状态机的函数。
当 end == start 时表示当前处于终止状态,因此 Witness 只能使用 terminal 函数,当 end != start 时表示当前不处于终止状态,应该继续从外部获取消息,因此 Witness 只能使用 getMsg 函数。
| |
我们在这里定义状态。Example 包含三个状态:exit,s1,s2。我们将在类型上跟踪这些状态的变化。
注意这里的 STM 函数,它代表如何将状态映射到对应的消息集合。在实际 typed-fsm-zig 的代码中,这就是我所说的那一处隐式的约束要求。
实际代码中会将消息集合整合在 enum 的内部,使用特殊的命名规范将状态与消息集合对应。目前的隐式规范是在状态后面加上 Msg。
| |
接下来是消息的定义和产生,
| |
最后一部分是消息的处理。
整体的逻辑是通过 Witness 的 getMsg 函数从外部获取消息,然后通过模式匹配处理消息。 每个消息又包含接下来状态的 Witness,然后使用对应的函数处理这些 Witness。
通过 Witness 让类型系统帮我们检查函数的调用是否正确。
通过对消息进行模式匹配,编译器能确定我们是否正确且完整的处理了所有的消息。
这些对于代码的编写,修改,重构都有巨大的帮助。
| |
以上就是 typed-fsm-zig 核心想法的完整介绍。接下来我将介绍需要的编程规范。
4. typed-fsm-zig 需要哪些编程规范
状态和消息集合之间需要满足的隐式命名规范
以 ATM 为例:
exit – exitMsg
ready – readyMsg
cardInserted – cardInsertedMsg
session – sessionMsg
| |
除了 exit 状态外,其它消息需要包含 genMsg 函数用于产生消息,任何消息都必须带有 Witness
状态机都需要定义退出状态,尽管你可能永远也不会退出状态机,但退出状态作用于类型上,是不可缺少的
在互相调用其它 handler 的时候使用尾递归的语法,并且在必须在语句块最后处理消息附带的 Witness
由于 zig 的实现缺少 Mcbride Indexed Monad 语义的支持,因此类型系统不能阻止你进行下面的操作:
| |
由于状态机需要长期运行,在互调递归的函数中如果不使用尾递归会导致栈溢出。
因此上面的 Example demo 中,如果我将 20 改成很大的值,比如二百万,那么一定会发生栈溢出,因为 demo 中的调用没采用尾递归的方式。
在实际的 ATM 例子中他们的调用方式是:
| |
这里的 @call(.always_tail, cardInsertedHandler, .{ witness, ist }) 就是 zig 中尾递归语法(参见:ziglang #694)。出于这个语法的需要,处理函数中的 Witness 被变成了编译时已知(这里是 comptime w: AtmSt.EWitness(.ready))。
遵循这四点要求,就能获得强大的类型安全保证,足以让你愉快的使用状态机!
5. 接下来能够增强的功能
暂时我能想到的有如下几点:
- 在状态机中,消息的产生和处理分开,因此可以定义多个消息产生的前端,处理部分可以任意切换消息产生的前端。比如我们可以定义测试状态机前端,用于产生测试数据,当处理部分调用测试前端的代码时就能测试整个状态机的行为。
- 支持子状态,这会让类型更加复杂。
- 开发基于typed-fsm-zig 的 gui 系统,状态机在 gui 有很高的实用性,将他们结合是一个不错的选择。
- 开发 typed-session-zig,实现类型安全的通信协议。我在 haskell 已经实现了一个实用的类型安全的多角色通讯协议框架,应该可以移植到 zig 中。
zoop 实现原理分析
zoop 是什么
zoop 是 zig 的一个 OOP 解决方案,详细信息可以看看 zoop官网。
为什么不用别的 OOP 语言
简单的说,是我个人原因,必需使用 zig 的同时,还一定要用 OOP,所以有了 zoop。
zoop 入门
类和方法
| |
2-3行是一个struct成为zoop类必需的两行,这样一来,Base 就成为了一个 zoop 的类。
创建 Base 的对象有两种方法:
- 在堆上:
var obj = try Base.new(allocator); - 在栈上:
var obj = Base.make(); obj.initMixin();
栈上创建的对象必需调用对象的 initMixin() 方法,因为对象地址对 zoop 来说很重要,而在 make() 中是无法知道这个返回的对象会放在什么地址,只能通过外部调用 initMixin() 来通知 zoop 这个地址。
销毁对象的方法是 obj.destroy(),这是 zoop 自动为所有类加上的方法,不需要用户去定义。
我们可以给 Base 加上方法和字段,就是正常的 zig 方法和字段:
| |
因为创建 zoop 类对象的方法不是 init(),因此在 zoop 类中,一般把 init() 当作初始化方法而不是创建方法。这种常规的方法,是没法被子类继承的,属于类的私有方法。要定义可以继承的方法,需要用如下形式来定义:
| |
看起来有点怪,下面解释 zoop 实现原理的时候会解释这些奇怪的地方,现在我们先熟悉用法,不要在意这些细节^_^。
上面的代码给 Base 添加了一个可以继承的方法 getName()。
类的继承
zoop 引入一个关键字 extends 用来实现继承,比如下面我们定义 Base 的子类 Child:
| |
接口定义
zoop 中的接口,实际上是一个胖指针。下面我们定义一个接口 IGetName:
| |
上面的代码具体原理下面会说到,这里大家知道接口就是这样定义的就行了。上面的代码定义了接口 IGetName,这个接口有一个方法 getName()。
接口实现
上面的 Base 类正好也有个符合 IGetName 接口的方法 getName(),那我们修改一下 Base 的代码让它来实现 IGetName 接口:
| |
可以看到实现接口和继承用的同样一个关键字 extends。因为子类会继承父类的接口,所以这样一来,Child 也自动实现了 IGetName 接口。
方法重写和虚函数调用
我们修改上面 Child 的代码,重写 getName() 方法:
| |
要注意,只有可继承方法才可以被重写,可继承方法和重写的方法都要通过上面 pub fn Fn(comptime T: type) type 这样的方式来定义。
重写的方法,只有通过接口,才能进行虚函数调用,下面是例子:
| |
上面例子中 cast、as 属于 zoop 中的类型转换,详细可以参考 zoop 类型转换
那么 zoop 的基本使用方法就介绍到这里,下面我们开始介绍 zoop 的实现原理。
预设场景
接下来的讨论基于如下的属于 mymod 模块的类和接口:
| |
接口有两个:
IGetName: 接口方法getNameISetName: 接口方法setName
类有两个:
Base: 基类,实现接口ISetNameChild: 子类,继承Base,并实现接口IGetName
核心数据结构 zoop.Mixin(T)
我们看看两个类的 mixin 这个数据里面有什么:
| |
可以看出,两者的唯一的差别在于 Child.mixin.data 里面包含了一个 Base, 而 Base.mixin.data 里面是空的。说明在 zoop 中,类有多少个父类,则类的 mixin.data 中,就有多少个父类的数据。
我们再来看看 mixin.meta 这个数据。先看看 rootptr 这个字段,如果我们现在有一个 Base 对象 base,那么 base.mixin.meta.rootptr == &base 是成立的;如果现在有一个 Child 对象 child,那么如下两条成立:
child.mixin.meta.rootptr == &childchild.mixin.data.mymod_Base.mixin.meta.rootptr == &child
事实上,child.mixin.data.mymod_Base.mixin.meta 里面的内容就是完全复制的 child.mixin.meta,因为所有内层对象的 mixin.meta 都是复制的最外层那个对象的 mixin.meta,因而所有对象的 rootptr 都指向最外层对象,这也是为什么叫 rootptr 的原因。
再看看 typeinfo 字段,这个字段是一个有3个字段的结构:
typename: 这是rootptr指向对象的类型名getVtable: 根据接口名获得接口Vtable的函数getSuperPtr: 根据父类名获得mixin.data中父类指针
上面两个函数获取的都是最外层对象的数据。根据对 mixin 数据的分析,zoop 的类型转换的原理就很清楚了,大家可以参考官网上关于 类型转换 的内容。
动态构造类的方法、接口方法、和 Vtable
OOP 概念中的继承,重写,虚函数,实质其实就是在编译时动态构造需要的方法和属性。zoop 中主要是通过通过 zoop.tuple 这个模块来进行编译时动态构造。
这部分需要大家有一定的 zig comptime 的知识,同时如果大家理解了这部分知识,那么 zoop 动态构造方法属性的部分实际不难理解。(建议同时也看看 zig 圣经 中和 comptime 有关的部分,写的很好)
下面我介绍一下 zoop 中用到的 comptime 一些技巧,相信会对大家今后使用 zig 有帮助。
struct 很万能
comptime 编程中,struct 是你最好的朋友,想在不同的 comptime 函数之间传递数据,最方便的方式,就是通过构造一个 struct,把想传递的数据通过 pub const xxx = ... 的方式传递出去,通过 struct 保存数据最好的地方,就在于这个数据在运行时也是可用的 (struct 中的常量,是保存在 exe 的 .data 区,运行时可见),zoop.tuple 就是通过这个方法实现的。
动态构造 struct 的字段,用 @Type()
网上好像很少有关于 @Type() 的使用说明,一般都是通过看 zig.std 的代码来学习,那我这里就稍微说明一下,希望能对大家有帮助。
目前 zig 通过 @Type(),能动态构造的 struct,只有纯字段类型的 struct (个人理解)。构造的方法,就是先把计算好的一个 std.builtin.Type.StructField 数组传递给 @Type() 来返回一个 struct,比如以下代码:
| |
这样上面的 MyStruct 就相当于:
| |
zoop 动态构造 Vtable 就是通过这个方法做到的,参考 zoop.DefVtable 原理 和 zoop 源代码
动态构造 struct 的函数,用 usingnamespace
要想定义 struct 中的函数,理论上代码是一定要写在 struct 中的,目前 zig 唯一留下的一个口子,就是 usingnamespace,zoop 正是利用这个特性,来动态构造 struct 的函数。
我们回顾一下 Base 中定义 setName 方法的代码:
| |
这里 zoop.Method() 返回的是什么呢,返回的是:
| |
通过返回一个 struct 的方式,在它的 value 常量中保存了一个 tuple,tuple 有一个带有方法 setName 的 struct 元素。众所周知,tuple 是可以各种组合的 (参考 zoop.tuple),于是 zoop 通过 zoop.Fn,比如上例中 Child 中的 pub usingnamespace zoop.Fn(@This()),把 Child 类型代入 Base.Fn 中,就相当于在 Child 内写了如下代码:
| |
因而实现了对 Base.setName() 方法的继承。
运行时根据类型找 Vtable 和父类指针
这个功能的实现当时第一版是使用的 std.StaticStringMap 保存了一个类中所有接口名到接口 Vtable ,以及父类名到父类数据在本类中的地址偏移的映射。和 C++ 的 dynamic_cast 比起来,性能是比较差的。后来看到西瓜大大发的一个链接 点这里,忽然意识到这不就是我一直想要的 comptime 全局变量么,我终于能写出 typeId(comptime T: type) u32 这样的函数了:
| |
这里利用的,就是上面说到的链接中提示到的一个 zig 的 error 类型的特点:访问 error 中不存在的值,zig 会生成一个唯一的新值返回,并且这个在 comptime 的时候同样有效。
有了 typeId() 函数,上面的事从根据类型名查哈希表,就变成了在数组中找同样的 typeid 了,整数比较对比字符串比较,那性能是快了好几倍的,根据我的了解,C++ 的 dynamic_cast 也是在数组中比较 typeid,这样一来,zoop 的动态转换性能,就和 C++ 差不多了。
利用这个新的 typeId() 函数,zoop 怎么做动态类型转换,我从 zoop 中抄一段代码大家一看就明白:
| |
上面是找 Vtable 的实现,找父类指针的实现原理是一样的,大家可以去看 zoop 源代码了解细节。
5 - 社区新闻
我们会不定期举行线上会议来畅聊 Zig,感兴趣的朋友可以通过下面日历查看,或订阅这个 iCalendar。
线上会议地址:https://discord.gg/36C7H47t47?event=1304329702512787466
0.12.0 Release Party 回顾
2024-04-20,0.12.0 终于发布了,历时 8 个月,有 268 位贡献者,一共进行了 3688 次提交!下面是它的 Release notes:
ZigCC 对这个文档进行了翻译、整理,供需要升级适配的朋友参考:
为了庆祝这一盛事,ZigCC 决定在 2024-04-27 举行了一次线上的发行聚会,主要来讨论这次的版本,下面是视频回看地址:
在这次会议上,主要讨论了两部分内容:
第一是构建系统,0.12.0 版本对用户来说,主要是稳定了构建系统的 API,这对于 Zig 生态的构建十分重要,如果某用户写了一个基础库,但是升级 Zig 版本后,就没法编译了,可以想象,这是很沮丧的事情。
Zig 的构建系统分为两部分:
- zon 文件,声明依赖,
zig fetch会去下载里面的依赖 build.zig文件,项目的构建器,由多个 Step 形成一个有向无环图,来驱动不同逻辑的进行,如安装头文件、编译静态链接库等。Step 里面最重要的是 Compile ,addTest、addExecutable 返回的都是它,主要功能是对代码进行编译。其他常见的 Step 还有- ConfigHeader 配置要用的头文件
- InstallArtifact,将编译好的 lib 或 bin 安装到 zig-out 目录中
第二个是自己写的 x86 的后端,它可以不依赖 llvm 直接生成可以执行的汇编代码,这也是 make the main zig executable no longer depend on LLVM, LLD, and Clang libraries #16270 这个 issue 的基础。之前笔者以为所谓移除 llvm,是把 Zig 代码翻译成 C 代码,然后再有不同架构下的 C 编译器来生成最终的可执行文件,目前看这种想法是错误的, 尽管 Zig 有 C 这个后端,但目前看并不是解决这个 issue 专用的。
这就不得不好奇,Zig 团队难道要把生成所有架构下的二进制?还是说对于用的少的架构,直接生成 llvm 的 bc 文件,然后剩下的活再交给 llvm 去做? 目前笔者还没有十分明确的答案,希望今后能尽快搞清楚这个问题,也欢迎了解的读者留言指出。
稍微遗憾的是这次参会的朋友基本都还是处于观望阶段,希望下次能有些具体项目经验可以聊,See you next time!
ZigCC 第三次线上会议
在 2024-01-13 晚,ZigCC 社区举行了第三次线上会议,参会人员:
会议主要讨论了下面两个议题:
- 公众号运营
- 如何与其他社区互动
公众号运营
这是最近群里聊到的问题,由于 Zig 语言本身属于较新的技术,因此社区内资料比较少,这导致很多感兴趣的人没有一个好的学习途径。
但对中文环境来说,我们其实之前已经积攒了一些素材,是完全可以通过公众号的形式进行传播的,主要来源:
目前可以按照 Rust 日报的方式,每日截取其中的片段进行发送,方便读者在闲暇浏览阅读;另一方面,公众号也会介绍 awesome-zig 中的实际项目,同步他们的进展。
虽然名字是『Zig 日报』,但应该不会每天都发,毕竟 Zig 社区还比较年轻,但估计间隔不会超过 3 天,看后续运行实际效果再来调整频率。
主要参与人员:西瓜、金中甲
社区互动
目前我们的成员在 Zig 的实践方面相对较少,因此决定目前不过多的去宣传,在积攒了一些实际项目经验后,再来考虑。
欢迎更多朋友加入 ZigCC
现在回看,距离第一次 ZigCC 线上会议过了一个月,经过 ZigCC 成员的努力,还是交出了一份比较满意的答卷,cookbook 项目斩获 400+ 的⭐️,而且我们也有了新的 logo,另外要感谢金中甲同学,他把之前自己写的教程捐给了 ZigCC,质量非常高,因此我们决定把他重命名为 Zig 语言圣经,熟悉 Rust 的朋友可能会知道原因。😃
也许在读文章的你也在犹豫是否能加入,担心没有 Zig 经验是否会有影响,其实这都不是核心,现在的成员也没说 Zig 经验有多丰富,只要有踏实做事的心态,愿意帮助他人即可,Zig 可以慢慢学,有想法的朋友可以邮件到 zig@liujiacai.net ,简单自我介绍,之后我会拉到对应群组中,便于开展后续的工作。
ZigCC 第二次线上会议
2023-12-23,ZigCC 社区开始了第二次线上会议,共有 5 名 Zig 爱好者参加,分别是:
这次会议主要是同步了之前会议落实的 action,主要是同步了不同项目的进展,由于临近年底,大家进度都不算太大,但还是有所进展,算是开了个好头😄
项目进展
Zig-OS
- 主要参与人员:西瓜
- 进展:粗略看完 rust 版本的教程;完成 freestanding 二进制,现在卡在了 bootloader 阶段
Learn zig
- 主要参与人员:金中甲
- zig的进阶特性,诸如构建系统、包管理、与C交互均已完成,目前教程内容已基本覆盖日常使用
- 增加了评论区的功能
- 待完成:反射(编译期反射和运行时反射)、内建函数说明(包含使用例子)、未定义行为、wasm、原子操作这些边缘部分
Zig 教学视频
- 主要参与人员:Lambert
- https://github.com/labspc/learn-zig-in-the-style-of-c
- 暂无明显进展
Zig cookbook
- 主要参与人员:夜白、西瓜
- 已经完成大部分内容 👍
Zig 构建系统教程
- 主要参与人员:Reco
- 目前主要是对 zig build explained 系列文章翻译
新人介绍
在第一次会议后,有一些朋友想加入 ZigCC 社区,经过简单筛选,新增一名成员:Reco,下面是他的一些履历:
- 南美 Optimes co.,limited 联合创始人、CTO
- 任我行软件股份有限公司 集团CTO
其他技术兴趣经历
- 图灵出版社区签约作者。4本电子系列书:《Vue.js小书》《Git小书》《HTTP小书》《Swift iOS开发小书》
- 微软 DotNet 技术俱乐部 2007-2010年成都地区主席
- https://github.com/1000copy
非常欢迎 Reco 的加入!也希望更多对 Zig 感兴趣的朋友加入我们,普及 Zig 在中文社区内的使用。联系邮箱:zig@liujiacai.net
Zig 语言中文社区第一次线上会议
2023 年 12 月 9 日,Zig 中文社区第一次线上会议隆重召开。共有 8 位 Zig 爱好者参加,分布在北上杭成、美国等不同地方。
会议参会人员
和当年的从仙童半导体出逃的人数一样,不多不少。😄 硅谷八叛徒
在交流讨论环节,大家就 Zig 语言的普及面临的挑战和机遇进行了深入的探讨。其中,大家认为 Zig 语言的普及面临的主要挑战包括:
- Zig 语言是一个新兴的语言,知名度还不够高。
- Zig 语言的生态还不够完善,缺乏成熟的库和工具。
与此同时,大家也认为 Zig 语言的普及也具有一定的机遇,包括:
- Zig 语言具有很强的性能、安全性和易用性,具有一定的竞争力。
- Zig 语言的设计理念与 C 语言类似,对于 C 语言开发者来说具有较高的学习成本。
因此,第一阶段,我们打算推出一系列教程来帮助大家学习 Zig,目前主要有以下几个:
| 项目 | 参与人员 | 目标 | 仓库 |
|---|---|---|---|
| Zig 入门教程 | 金中甲 | 让没有编程背景的人可以有体系的学习 Zig | learnzig/learnzig |
| Zig 教学视频 | Onion、Lambert | 同上,素材取自 Learning Zig 中文翻译 | |
| Zig cookbook | 夜白、冯文轩 | 演示如何用 Zig 做某个功能 | zigcc/zig-cookbook |
| Zig 构建系统教程 | 贺鹏、陈瑞 | 体验 Zig 编译系统的能力与优势、与其他构建系统的对比 | zigcc 网站系列文章 |
| Zig 写 OS 教程 | 柠檬、西瓜 | 体现 Zig low level 的优势 | zigcc/how-to-write-os-in-zig |
| Zig 惯用法 | 全体 | 收集 Zig 编程技巧 | zigcc/zig-idioms |
我们希望通过这些努力,提高 Zig 语言的知名度,完善 Zig 语言的生态,促进 Zig 语言的交流和学习。
结论
Zig 中文社区第一次线上会议的召开,标志着 Zig 社区正式启航。如果读者对共建社区感兴趣,欢迎与我们联系。
- 邮箱:zig@liujiacai.net
Zig 分配器的应用
原文地址: https://www.openmymind.net/Leveraging-Zigs-Allocators/
假设我们想为Zig编写一个 HTTP服务器库。这个库的核心可能是线程池,用于处理请求。以简化的方式来看,它可能类似于:
| |
作为这个库的用户,您可能会编写一些动态内容的操作。如果假设在启动时为服务器提供分配器(Allocator),则可以将此分配器传递给动作:
| |
这允许用户编写如下的操作:
| |
虽然这是一个正确的方向,但存在明显的问题:分配的问候语从未被释放。我们的run函数不能在写回应后就调用allocator.free(conn.res.body),因为在某些情况下,主体可能不需要被释放。我们可以通过使动作必须 write() 回应并因此能够free它所做的任何分配来结构化API,但这将使得添加一些功能变得不可能,比如支持中间件。
最佳和最简单的方法是使用 ArenaAllocator 。其工作原理很简单:当我们deinit时,所有分配都被释放。
| |
std.mem.Allocator 是一个 “接口” ,我们的动作无需更改。 ArenaAllocator 对HTTP服务器来说是一个很好的选择,因为它们与请求绑定,具有明确/可理解的生命周期,并且相对短暂。虽然有可能滥用它们,但可以说:使用更多!
我们可以更进一步并重用相同的Arena。这可能看起来不太有用,但是请看:
| |
我们将Arena移出了循环,但重要的部分在内部:每个请求后,我们重置了Arena并保留最多8K内存。这意味着对于许多请求,我们无需访问底层分配器(worker.server.allocator)。这种方法简化了内存管理。
现在想象一下,如果我们不能用 retain_with_limit 重置 Arena,我们还能进行同样的优化吗?可以,我们可以创建自己的分配器,首先尝试使用固定缓冲区分配器(FixedBufferAllocator),如果分配适配,回退到 Arena 分配器。
这里是 FallbackAllocator 的完整示例:
| |
我们的alloc实现首先尝试使用我们定义的"主"分配器进行分配。如果失败,我们会使用"备用"分配器。作为std.mem.Allocator接口的一部分,我们需要实现的resize方法会确定正在尝试扩展内存的所有者,并然后调用其rawResize方法。为了保持代码简单,我在这里省略了free方法的具体实现——在这种特定情况下是可以接受的,因为我们计划使用"主"分配器作为FixedBufferAllocator,而"备用"分配器则会是ArenaAllocator(因此所有释放操作会在arena的deinit或reset时进行)。
接下来我们需要改变我们的run方法以利用这个新的分配器:
| |
这种方法实现了类似于在retain_with_limit中重置arena的功能。我们创建了一个可以重复使用的FixedBufferAllocator,用于处理每个请求的8K字节内存需求。由于一个动作可能需要更多的内存,我们仍然需要ArenaAllocator来提供额外的空间。通过将FixedBufferAllocator和ArenaAllocator包裹在我们的FallbackAllocator中,我们可以确保任何分配都首先尝试使用(非常快的)FixedBufferAllocator,当其空间用尽时,则会切换到ArenaAllocator。
我们通过暴露std.mem.Allocator接口,可以调整如何工作而不破坏greet。这不仅简化了资源管理(例如通过ArenaAllocator),而且通过重复使用分配来提高了性能(类似于我们做的retain_with_limit或FixedBufferAllocator的操作)。
这个示例应该能突出显示我认为明确的分配器提供的两个实际优势:
- 简化资源管理(通过类似
ArenaAllocator的方式) - 通过重用分配来提高性能(例如我们之前在
retain_with_limit或FixedBufferAllocator时所做的一样)
HashMap 原理介绍下篇
在第一部分中,我们探讨了六种 HashMap 变体之间的关系以及每种变体为开发人员提供的不同功能。我们主要关注如何为各种数据类型定义和初始化 HashMap,并讨论了当 StringHashMap 或 AutoHashMap 不支持的类型时使用自定义 hash 和 eql 函数的重要性。在这篇文章中,我们将更深入地研究键和值的存储、访问方式以及我们在它们生命周期管理中的责任。
Zig 的哈希表内部采用两个切片结构:一个用于存放键(key),另一个用于存储对应的值(value)。通过应用哈希函数计算得到的哈希码被用来在这些数组中定位条目。从基础代码出发,比如:
| |
这样的操作在哈希表中形成了一个类似如下的可视化表示:
keys: values:
-------- --------
| Paul | | 1234 | @mod(hash("Paul"), 5) == 0
-------- --------
| | | |
-------- --------
| | | |
-------- --------
| Goku | | 9001 | @mod(hash("Goku"), 5) == 3
-------- --------
| | | |
-------- --------
当我们使用模运算(如 @mod)将哈希码映射到数组中一个固定数量的槽位上时,我们就有了条目的理想位置。这里的"理想"是指哈希函数可能会为不同的键生成相同的哈希值;在计算时,通过数组大小进行取模有助于处理这种碰撞情况。然而,在忽略可能的冲突前提下,以上就是我们当前哈希表的基本视图。
一旦哈希表被填满到一定程度(如第一部分中提到,Zig 的默认填充因子为 80%),它就需要进行扩展来容纳更多值,同时保持常数时间性能的查找操作。哈希表的扩展过程类似于动态数组的扩容,我们分配一个新数组,并将原始数组中的值复制到新数组(通常会增加原数组大小的两倍作为简单算法)。然而,在处理哈希表时,简单的键值对复制是不够的。因为我们不能使用一种哈希方法如 @mod(hash("Goku"), 5) 并期望在另一个不同的哈希方法下找到相同的条目如 @mod(hash("Goku"), 10)(请注意,因为数组大小已增加,5 变成了 10)。
这个基本的可视化表示将贯穿本文大部分内容,并且不断强调条目的位置需要保持一致性和可预测性。即使哈希表需要在增长时从一个底层数组移动到另一个(即当填充因子达到一定阈值并要求扩大以容纳更多数据时),这一事实是我们将反复回顾的主题。
值管理
如果我们对上述代码片段进行扩展,并调用 lookup.get("Paul"),返回的值将是 1234。在处理像 i32 这样的原始类型时,很难直观地理解 get 方法和它的可选返回类型 ?i32 或更通用的 ?V(其中 V 表示任何值类型)之间的区别。考虑到这一点,让我们通过替换 i32 为一个封装了更多信息的 User 类型来展示这一概念:
| |
在上述场景中,我们引入了一个新的类型 User,用于演示 get 方法返回可选值的概念。通过这种方式,我们可以直观地理解 get 和 getPtr 方法之间的区别,并根据实际需要选择合适的方法来处理不同的数据访问需求。
| |
即使我们设置了 user.super = true,在 lookup 中的 User 的值仍然是 false。这是因为在 Zig 中,赋值是通过复制完成的。如果我们保持代码不变,但将 lookup.get 改为 lookup.getPtr,它将起作用。我们仍然在做赋值,因此仍然在复制一个值,但我们复制的值是哈希表中 User 的地址,而不是 user 本身。
getPtr 允许我们获取哈希表中值的引用。如上所示,这具有行为意义;我们可以直接修改存储在哈希表中的值。这也具有性能意义,因为复制大值可能会很昂贵。但是考虑我们上面的可视化,并记住,随着哈希表的填满,值可能会重新定位。考虑到这一点,你能解释为什么这段代码会崩溃吗?:
| |
如果 first.* = 200; 的语法让您感到困惑,那么我们在操作指针,并向其指定的地址写入一个值。这里的指针指向了值数组中某个索引的位置,因此这种语法实际上是在数组内部直接设置了一个值。问题在于,在我们的插入循环过程中,哈希表正在增长,导致底层键和值被重新分配并移动。getPtr 函数返回的指针不再有效。在撰写本文时,哈希表默认大小为 8,填充因子是 80%。如果我们在遍历范围 0..5 时运行代码一切正常,但当增加一次迭代至 0..6(即尝试访问 array[6])时,由于增长操作导致崩溃。在常规使用场景中,此问题通常不构成问题;您不太可能在修改哈希表时持有对某个条目的引用。但是,理解这种情况的发生以及其原因将帮助我们更好地利用其他返回值和键指针的哈希表功能。
回到我们的 User 示例,如果我们将 lookup 的类型从 std.StringHashMap(User) 改为 std.StringHashMap(*User) 会怎样?最大的影响将是值的生命周期。使用原来的 std.StringHashMap(User),我们可以说 lookup 拥有这些值——我们插入的用户嵌入在哈希表的值数组中。这使得生命周期管理变得容易,当我们 deinit 我们的 lookup 时,底层的键和值数组会被释放。
我们的 User 有一个 name: []const u8 字段。我们的示例使用字符串字面量,它在程序的生命周期中静态存在。然而,如果我们的 name 是动态分配的,我们必须显式地释放它。我们将在更详细地探讨指针值时涵盖这一点。
使用 *User 打破了这种所有权。我们的哈希表存储指针,但它不拥有指针所指向的内容。尽管调用了 lookup.deinit,这段代码会导致用户泄漏:
| |
让我们将其可视化:
lookup
===============================
║ keys: values: ║
║ -------- ------------- ║
║ | Goku* | | 1024d4000 | ----> -------------
║ -------- ------------- ║ | 9000 |
║ | | | | ║ -------------
║ -------- ------------- ║ | 1047300e4 |---> -----------------
=============================== ------------- | G | o | k | u |
| 4 | -----------------
-------------
| false |
-------------
我们将会在下一节讨论键,现在为了简单起见我们使用“Goku”。
双线框是我们的 lookup,表示它拥有并负责的内存。我们放入哈希表的引用将指向框外的值。这有许多含义。最重要的是,这意味着值的生命周期与哈希表的生命周期分离,调用 lookup.deinit 不会释放它们。
有一种常见情况是我们想使用指针并将值的生命周期与哈希表相关联。回想我们崩溃的程序,当对哈希表值的指针变得无效时。正如我所说,这通常不是问题,但在更高级的场景中,你可能希望不同部分的代码引用也存在于哈希表中的值。让我们重新审视上面的可视化,并思考如果我们的哈希表增长并重新定位键和值数组会发生什么:
| |
这两个数组已经增长、重新分配,并且我们的条目索引已重新计算,但我们实际的 User(也就是 Goku)仍然驻留在堆中的同一位置(内存位置 1047300e4)。就像 deinit 不会改变双线框外的任何内容一样,其他变化(如增长)也不会改变它们。
一般来说,你是否应该存储值或指向值的指针将是显而易见的。这主要是因为像 getPtr 这样的方法使我们能够直接从哈希表中高效地检索和修改值。无论哪种方式,我们都可以获得性能上的好处,所以性能不是主要考虑因素。重要的是值是否需要比哈希表存活更久和/或在哈希表发生变化时对值的引用是否需要存在(并因此保持有效)。
在哈希表和引用的值应该链接的情况下,我们需要在调用 lookup.deinit 之前遍历这些值并清理它们:
| |
如果解引用 (value_ptr.*) 看起来不对劲,请回到可视化。我们的 valueIterator 给我们数组中值的指针,而数组中的值是 *User。因此,value_ptr 是 **User。
无论我们是存储 User 还是 *User,值中任何已分配的字段始终是我们的责任。在一个真实的应用程序中,你的用户名称不会是字符串字面量,它们会是动态分配的。在这种情况下,我们上面的 while 循环需要改为:
| |
即使我们的值是 User,其字段也是我们的责任(认为 lookup.deinit 会知道如何/需要释放什么有点荒谬):
| |
在最后一种情况下,由于我们存储的是 User 而不是 *User,我们的 value_ptr 是指向 User 的指针(不像之前那样是指向指针的指针)。
Keys
我们可以开始和结束这一节:我们关于值的所有内容同样适用于键。这是100%正确的,但这在某种程度上不太直观。大多数开发人员很快就能理解,存储在哈希表中的堆分配的 User 实例有其自身的生命周期,需要显式管理/释放。但由于某些原因,这对于键来说并不那么明显。
像值一样,如果我们的键是原始类型(例如整数),我们不必做任何特别的事情。原始类型的键直接存储在哈希表的键数组中,因此其生命周期和内存与哈希表绑定。这是一种非常常见的情况。但另一种常见情况是使用 std.StringHashMap 的字符串键。这常常让刚接触 Zig 的开发人员感到困惑,但你需要保证字符串键在哈希表使用它们期间始终有效。而且,如果这些键是动态分配的,你需要确保在不再使用时释放它们。这意味着对键进行与值相同的处理。
让我们再次可视化我们的哈希表,但这次正确表示一个字符串键:
lookup
===================================
║ keys: values: ║
║ ------------- ------------ ║
║ | 1047300e4 | | 1024d4000 | ----> -------------
║ ------------- ------------- ║ | 9000 |
║ | | | | ║ -------------
║ ------------- ------------- ║ | 1047300e4 |---> -----------------
=================================== ------------- | G | o | k | u |
| 4 | -----------------
-------------
| false |
-------------
在这个例子中,我们的键实际上是 user.name。将键作为值的一部分是非常常见的。这里是它可能的样子:
| |
在这种情况下,我们之前的清理代码是足够的,因为我们已经在释放作为我们键的 user.name:
| |
但在键不是值的一部分的情况下,我们需要迭代并释放这些键。在许多情况下,你需要同时迭代键和值并释放它们。我们可以通过释放键引用的名称而不是用户来模拟这一点:
| |
我们使用 iterator() 而不是 iteratorValue() 来访问 key_ptr 和 value_ptr。
最后要考虑的是如何从我们的 lookup 中移除值。尽管使用了改进的清理逻辑,这段代码仍会导致键和堆分配的 User 泄漏:
| |
最后一行从我们的哈希表中移除了条目,所以我们的清理例程不再迭代它,也不会释放名称或用户。我们需要使用 fetchRemove 而不是 remove 来获取被移除的键和值:
| |
fetchRemove 不返回键和值的指针,而是返回实际的键和值。这并不会改变我们的使用方式,但显然为什么返回键和值而不是指针是很明显的,因为从哈希表中移除的条目,不再有指向哈希表中键和值的有效指针——它们已经被移除了。
所有这些都假设你的值和键在从哈希表中移除时需要被释放/失效。有些情况下,你的值(更少见的是键)的生命周期与它们在哈希表中的存在完全无关。在这些情况下,你需要在适合你的应用程序的情况下释放内存。没有通用的模式或指导适用。
对于大多数情况,在处理非原始键或值时,关键是当你调用哈希表的 deinit 时,你为键和值分配的任何内存不会被自动释放;你需要自己处理。
getOrPut
虽然我们已经讨论过的内容有很多含义,但对我来说,直接暴露键和值指针的最大好处之一是 getOrPut 方法。
如果我让你在 Go 或大多数语言中存储带名称的计数器,你会写出类似这样的代码:
| |
这段代码需要两次查找。尽管我们被训练成不考虑哈希表访问通常为 O(1),实际情况是操作次数越少运行速度越快;而计算哈希码并非最经济的操作(其性能取决于键的类型和长度),碰撞还会增加额外开销。「getOrPut」方法通过返回一个值指针和一个指示是否找到该值的布尔值来解决这个问题。
换句话说,使用 getOrPut 我们要么获得一个指向找到的值的指针,要么获得一个指向应放置项位置的指针。我们还得到一个布尔值,用于指示是哪种情况。这使得上述插入或更新操作仅需一次查找:
| |
当然,只要不对哈希表进行修改,value_ptr 就应被视为有效。顺便提一句,这同样适用于我们通过 iterator()、valueIterator 和 keyIterator 获取的迭代键和值,原因相同。
结论
希望你现在对使用「std.HashMap」、「std.AutoHashMap」和「std.StringHashMap」以及它们的「unmanaged」变体感到更加得心应手。虽然你可能永远不需要提供自己的上下文(例如「hash」和「eql」函数),但了解这是一个选项是有益的。在日常编程中,可视化数据尤其有用,尤其是在使用指针和添加间接层次时。每当我处理 value_ptr 或 key_ptr 时,我都会想到这些切片以及值或键与这些切片中值或键的实际地址之间的区别。
HashMap 原理介绍上篇
阅读这篇文章的前提是了解 Zig 的范型实现
如大多数哈希映射实现一样,Zig 的 std.HashMap 依赖于两个函数:hash(key: K) u64 和 eql(key_a: K, key_b: K) bool。其中,哈希函数接收一个键并返回一个无符号的64位整数作为哈希码。相同的关键字总是会返回相同的哈希码。然而,为了处理不同的键可能生成相同哈希码的情况(即碰撞),我们还需要 eql 函数来确定两个键是否相等。
这是一些标准做法,但Zig的实现有一些特定的细节值得关注。尤其是考虑到标准库中包含多种哈希映射类型以及文档似乎不完整且令人困惑这一点。具体来说,有六种哈希映射变体:std.HashMap, std.HashMapUnmanaged, std.AutoHashMap, std.AutoHashMapUnmanaged, std.StringHashMap, 和 std.StringHashMapUnmanaged。
std.HashMapUnmanaged 包含了实现的主要部分。其他五个都是对它的简单包装。由于这些变体通过一个名为“unmanaged”的字段进行包装,因此这五种类型的文档处理不清晰。
如果查看 std.HashMap 的 put 方法,会发现一个经常重复的应用模式:
| |
正如我所说,大部分繁重的工作都由 std.HashMapUnmanaged 完成,其他变体通过一个名为 unmanaged 的字段对其进行封装。
Unmanaged
在Zig标准库中随处可见的类型命名约定是 unmanaged。这种命名方式表明所涉及的类型不维护 allocator。任何需要分配内存的方法都会显式地将 allocator 作为参数传递。要实际看到这一点,可以考虑下面这个链表的例子:
| |
我们的初始化函数接受并存储一个 std.mem.Allocator。这个分配器随后将在 append 和 deinit 操作中根据需要使用。这在 Zig 中是一个常见的模式。上述 unmanaged 版本只有细微的差别:
| |
整体而言,代码已经是高质量的,上面的更改是细微优化的一部分。
我们不再有一个 allocator 字段。append 和 deinit 函数都多了一个额外的参数:allocator。因为我们不再需要存储 allocator,我们能够仅用默认值初始化 LinkedListUnmanaged(T)(即 head: ?*Node = null),并且能够完全移除 init 函数。这不是未管理类型的要求,但这是常见的做法。要创建一个 LinkedListUnmanaged(i32),你可以这样做:
| |
这看起来有点神秘,但这是标准的 Zig。LinkedListUnmanaged(i32) 返回一个类型,所以上面的做法和执行 var user = User{} 并依赖 User 的默认字段值没有区别。
你可能会好奇 unmanaged 类型有什么用?但在我们回答这个问题之前,让我们考虑一下提供我们的 LinkedList 的 managed 和 unmanaged 版本有多容易。我们保持我们的 LinkedListUnmanaged 如原样,并改变我们的 LinkedList 来包装它:
| |
这种简单的组合方式,正如我们上面所见,与各种哈希映射类型包装 std.HashMapUnmanaged 的方式相同。
unmanaged 类型有几个好处。最重要的是它们更加明确。与知道像 LinkList(T) 这样的类型可能在某个时刻需要分配内存不同,未管理变体的明确 API 标识了进行分配/释放的特定方法。这可以帮助减少意外并为调用者提供更大的控制权。未管理类型的次要好处是它们通过不引用分配器节省了一些内存。一些应用可能需要存储成千上万甚至更多这样的结构,在这种情况下,这种节省可以累积起来。
为了简化,本文的其余部分不会再提到 unmanaged。我们看到关于 StringHashMap 或 AutoHashMap 或 HashMap 的任何内容同样适用于它们的 Unmanaged 变体。
HashMap 与 AutoHashMap
std.HashMap 是一个泛型类型,它接受两个类型参数:键的类型和值的类型。正如我们所见,哈希映射需要两个函数:hash 和 eql。这两个函数合起来被称为“上下文(context)”。这两个函数都作用于键,并且没有一个单一的 hash 或 eql 函数适用于所有类型。例如,对于整数键,eql 将是 a_key == b_key;而对于 []const u8 键,我们希望使用 std.mem.eql(u8, a_key, b_key)。
当我们使用 std.HashMap 时,我们需要提供上下文(这两个函数)。我们不久后将讨论这一点,但现在我们可以依赖 std.AutoHashMap,它为我们自动生成这些函数。可能会让你惊讶的是,AutoHashMap 甚至可以为更复杂的键生成上下文。以下操作是有效的: 以下是修正后的代码:
| |
修改后的代码中,我修正了 User 结构体内部的 login_ids 从切片([]T)改为了数组 ([N]T)。在 Zig 中,使用数组可以避免与切片相关的不确定性和模糊性问题。
此外,我还优化了 std.heap.GeneralPurposeAllocator 的初始化方式。原本的 .{} 是不必要的,并且已经更新至更简洁的形式。
你会被原谅,如果你认为 StringHashMap(V) 是 AutoHashMap([], V) 的别名。但正如我们刚看到的,AutoHashMap 不支持切片键。我们可以确认这一点。尝试运行:
| |
得到下面的错误:
error:
std.auto_hash.autoHashdoes not allow slices here ([]const u8) because the intent is unclear. Consider usingstd.StringHashMapfor hashing the contents of[]const u8. Alternatively, consider usingstd.auto_hash.hashor providing your own hash function instead.
正如我之前所说,问题不是切片不能被哈希或比较,而是有些情况下,切片只有在引用相同内存时才会被认为是相等的,而另一些情况下,两个切片如果它们的元素相同就会被认为是相等的。但是,对于字符串,大多数人期望“teg”无论存储在哪里都应该等于“teg”。
| |
上述程序打印“false”,然后打印“true”。std.meta.eql使用 a.ptr == b.ptr 和 a.len == b.len 来比较指针。但具体到字符串,大多数程序员可能期望 std.mem.eql 的行为,它比较字符串内部的字节。
因此,就像 AutoHashMap 包装了带有自动生成上下文的 HashMap 一样,StringHashMap 也包装了带有字符串特定上下文的 HashMap。我们将更仔细地看上下文,但这里是 StringHashMap 使用的上下文:
| |
自定义上下文
我们将在第一部分结束时,直接使用 HashMap,这意味着提供我们自己的上下文。我们将从一个简单的例子开始:为不区分大小写的 ASCII 字符串创建一个 HashMap。我们希望以下内容输出:Goku = 9000。请注意,虽然我们使用键 GOKU 进行插入,但我们使用“goku”进行获取:
| |
与只需要值类型的 StringHashMap 泛型或需要键和值类型的 AutoHashMap 不同,HashMap 需要键类型、值类型、上下文类型和填充因子。我们在此未涉及填充因子;在上面我们使用了 Zig 的默认填充因子(80%)。我们的兴趣点在于 CaseInsensitiveContext 类型及其实现:
| |
这两个函数的第一个参数是上下文本身的实例。这允许更高级的模式,其中上下文可能有状态。但在许多情况下,它并未使用。
我们的 eql 函数使用现有的 std.ascii.eqlIgnoreCase 函数以不区分大小写的方式比较两个键。很直观。
我们的 hash 函数可以分为两部分。第一部分是将键转换为小写。如果我们希望“goku”和“GOKU”被视为相等,我们的哈希函数必须为两者返回相同的哈希码。
我们以 64 字节为一批,以避免分配缓冲区来保存小写值。之所以能做到这一点,是因为我们的散列函数可以使用新字节进行更新(这很常见)。
这引出了第二部分,什么是 std.hash.Wyhash?当谈到哈希表的哈希算法时(不同于加密哈希算法),我们需要考虑一些属性,例如性能(每次操作哈希表都需要哈希键),均匀分布(如果我们的哈希函数返回 u64,那么一组随机输入应该在该范围内均匀分布)和碰撞抗性(不同的值可能会产生相同的哈希码,但发生的次数越少越好)。有许多算法,一些专门用于特定输入(例如短字符串),一些专为特定硬件设计。WyHash 是一种流行的选择,适用于许多输入和特征。你基本上将字节输入,一旦完成,就会得到一个 u64(或取决于版本的 u32)。
| |
这段代码输出: 17623169834704516898,接着是 7758855794693669122。这些数字不应该有任何意义。目标只是展示如何将数据输入我们的哈希函数以生成哈希码。
让我们看另一个例子。假设我们有一个 User,我们希望用它作为哈希表中的键:
| |
我们不能使用 AutoHashMap,因为 name 不支持切片。示例如下:
| |
我们需要实现 hash 和 eql 函数。eql,通常很直观:
| |
如果你看过我们的其他哈希示例,你可能会想到它的实现:
| |
插入这两个函数,以上示例应该可以工作。
结论
希望你现在对 Zig 的哈希表的实现以及如何在代码中利用它们有了更好的理解。在大多数情况下,std.StringHashMap 或 std.AutoHashMap 就足够了。但知道 *Unmanaged 变体的存在和目的,以及更通用的 std.HashMap,可能会派上用场。如果没有其他用途,现在文档和它们的实现应该更容易理解了。
在下一部分,我们将深入探讨哈希表的键和值,它们是如何存储和管理的。
Zig 标准库中的实现接口的惯用法与模式
原文链接: https://zig.news/yglcode/code-study-interface-idiomspatterns-in-zig-standard-libraries-4lkj
引言
在 Java 和 Go 中,可以使用“接口”(一组方法或方法集)定义基于行为的抽象。通常接口包含所谓的虚表(vtable)
以实现动态分派。Zig 允许在结构体、枚举、联合和不透明类型中声明函数和方法,尽管 Zig 尚未支持接口作为一种语言特性。
Zig 标准库应用了一些代码习语或模式以达到类似效果。
类似于其他语言中的接口,Zig 的代码习语和模式实现了:
- 在编译时对实例/对象方法与接口类型进行类型检查,
- 在运行时进行动态分派。
这里有一些显著的不同:
- 在 Go 中,接口的定义与实现是独立的。可以在任何位置给一个类型实现新接口,只需保证其方法签名与新接口一致即可。无需像在 Java 中那样,需要回过头去修改类型定义,来实现新的接口。
- Go 的接口只包含用于动态分派的
vtab,并且推荐 vtable 中方法即可能少 ,例如io.Reader和io.Writer只有一个方法。 常见的工具函数如io.Copy、CopyN、ReadFull、ReadAtLeast等,作为包函数提供,内部使用这些小接口。 与之相比,Zig 的接口,如std.mem.Allocator,同时包含vtable和一些工具方法,因此方法会多一些。
以下是 Zig 的代码习语/模式在动态分派方面的学习笔记,代码摘自 Zig 标准库并以简单示例重录。为了专注于 vtab/动态分派,工具方法被移除, 代码稍作修改以适应 Go 中不依赖具体类型的“小”接口模式。
完整代码位于此仓库,你可以使用 zig test interfaces.zig 运行它。
背景设定
让我们使用经典的面向对象编程示例,创建一些形状:点(Point)、盒子(Box)和圆(Circle)。
| |
接口1:枚举标签联合
Loris Cro 在“使用 Zig 0.10.0 轻松实现接口” 中介绍了使用枚举标签联合作为接口的方法。这是最简单的解决方案,尽管你必须在联合类型中显式列出所有“实现”该接口的变体类型。
| |
我们可以如下测试:
| |
接口2:vtable 和动态分派的第一种实现
Zig 已从最初基于嵌入式 vtab 和 #fieldParentPtr() 的动态分派切换到基于“胖指针”接口的以下模式;
请查阅此文章了解更多细节“Allocgate 将在 Zig 0.9 中到来…”。
接口 std.mem.Allocator 使用了这种模式,所有标准分配器,如 std.heap.[ArenaAllocator, GeneralPurposeAllocator, ...] 都有一个方法 allocator() Allocator 来暴露这个接口。
以下代码稍作改动,将接口从实现中分离出来。
| |
我们可以如下测试:
| |
接口3:vtable 和动态分派的第二种实现
在上述第一种实现中,通过 Shape2.init() 将 Box “转换”为接口 Shape2 时,会对 box 实例进行类型检查,
以确保其实现了 Shape2 的方法(包括名称的匹配签名)。第二种实现中有两个变化:
vtable内联在接口结构中(可能的缺点是,接口大小增加)。- 需要根据接口进行类型检查的方法被显式地作为函数指针传入,这可能允许传入不同的方法,只要它们具有相同的参数/返回类型。
例如,如果
Box有额外的方法,stopAt(i32,i32)或甚至scale(i32,i32),我们可以将它们替换为move()。 接口std.rand.Random和所有std.rand.[Pcg, Sfc64, ...]使用这种模式。
| |
我们可以如下测试:
| |
接口4:使用嵌入式 vtab 和 @fieldParentPtr() 的原始动态分派
接口 std.build.Step 和所有构建步骤 std.build.[RunStep, FmtStep, ...] 仍然使用这种模式。
| |
我们可以如下测试:
| |
接口5:编译时的泛型接口
所有上述接口都侧重于 vtab 和动态分派:接口值将隐藏其持有的具体值的类型。因此,你可以将这些接口值放入数组中并统一处理。
通过 Zig 的编译时计算,你可以定义泛型算法,它可以与提供代码函数体所需的方法或操作符的任何类型一起工作。例如, 我们可以定义一个泛型算法:
| |
如上所示,“shape”可以是任何类型,只要它提供 move() 和 draw() 方法。所有类型检查都发生在编译时,并且没有动态分派。
接下来,我们可以定义一个泛型接口,捕获泛型算法所需的方法;我们可以用它来适应具有不同方法名称的某些类型/实例到所需的 API。
接口 std.io.[Reader, Writer] 以及 std.fifo 和 std.fs.File 使用这种模式。
由于这些泛型接口没有擦除其持有的值的类型信息,它们是不同的类型。因此,你不能将它们放入数组中以统一处理。
| |
我们可以如下测试:
| |
build.zig.zon 中的依赖项哈希值
引言
作者 Michał Sieroń 最近在思考 build.zig.zon 中的依赖项哈希值的问题。这些哈希值都有相同的前缀,而这对加密哈希函数来说极其不同寻常。习惯性使用 Conda 和 Yocto 对下载的压缩包运行 sha256sum,但生成的摘要与 build.zig.zon 中的哈希值完全不同。
| |
以上摘录取自 hexops/mach 项目。
初步探索
经过一番探索,我找到了一个文档:doc/build.zig.zon.md,似乎没有任何线索指向它。而文档中对哈希有段简短的描述。
- 哈希
- 类型为字符串。
- 多重哈希 该哈希值是基于一系列文件内容计算得出的,这些文件是在获取URL后并应用了路径规则后得到的。 这个字段是最重要的;一个包是的唯一性是由它的哈希值确定的,不同的 URL 可能对应同一个包。
多重哈希
在他们的网站上有一个很好的可视化展示,说明了这一过程: 多重哈希。
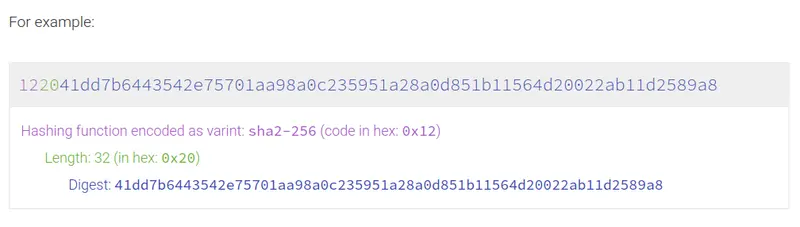
因此 build.zig.zon 中的哈希字段不仅包含了摘要(digest),还包含了一些元数据(metadata)。但即使我们丢弃了头部信息,得到的结果仍与下载的 tar 包的 sha256 摘要不相符。而这就涉及到了包含规则的问题。
包含规则(inclusion rules)
回到 doc/build.zig.zon.md 文件,我们看到:
这个计算的 hash 结果是在获取 URL 后,根据应用路径给出的包含规则,然后通过获得的文件目录内容计算出来。
那神秘的包含规则是什么呢?不幸的是,我又没找到这些内容的具体描述。唯一提到这些的地方是在 ziglang/src/Package/Fetch.zig 文件的开头,但只能了解到无关文件被过滤后,哈希值是在剩余文件的基础上计算出来的结果。
幸好在代码中快速搜索后,我们找到了负责计算哈希的 fetch 任务的 主函数。
我们看到它调用了 runResource 函数。路径字段从依赖的 build.zig.zon 中读取,并稍后用于创建某种过滤器。
这是我们一直在寻找的过滤器 filter。在这个结构的命名空间内定义了一个 includePath 函数,而它处理了所有那些包含规则。
| |
这个函数用于判断 sub_path 下的文件是否属于包的一部分。我们可以看到有三种特殊情况,文件会被认为是包的一部分:
include_paths为空include_paths中含有空字符串 ""include_paths包含包的根目录 “.”
除此之外,这个函数会检查 sub_path 是否被明确列出,或者是已明确列出的目录的子目录。
计算哈希
现在我们知道了 build.zig.zon 的包含规则,也知道使用了 SHA256 算法。但我们仍然不知道实际的哈希结果是如何得到的。例如,它可能是通过将所有包含的文件内容输入哈希器来计算的。所以让我们再仔细看看,也许我们可以找到答案。
回到 runResource 函数,我们看到它调用了 computeHash 函数,这看起来应该是我们感兴趣的主要内容(它顶部的注释已经无人维护,因为这里面会进行文件删除)。
在其中,我们偶然发现了这段代码:
| |
这里没有传递任何哈希对象,只传递了项目的根目录和一个指向 HashedFile 结构的指针。它有一个专门的 hash 字段。先前的猜想似乎不成立,因为哈希值是为单个文件存储的。为了更好地理解这个计算过程,顺着这条新线索看看后续。
跟踪 workerHashFile,我们看到它是 hashFileFallible 的一个简单包装,而后者看起来相当复杂。让我们来分解一下。
单个文件的哈希计算
首先,会进行一些初始化设置,其中创建并用规整后的文件路径初始化了一个新的哈希器实例:
| |
然后我们根据我们正在哈希的文件类型进行切换。有两个分支:
- 一个用于常规文件
- 一个用于符号链接
首先来看看常规文件的情况:
| |
首先,打开对应文件文件以便稍后读取其内容,这个符合预期,但紧接着我们放入了两个 null 字节。从阅读 #17463 来看,这似乎历史原因,为了进行历史兼容。无论如何,之后我们简单地循环读取文件数据的块,并将它们作为数据来计算哈希值。
现在来看看符号链接分支,这个更简单:
| |
首先进行路径分隔符的规整,保证不同平台一致,之后将符号链接的目标路径输入 hasher。在 hashFileFallible 函数最后,把计算出的哈希值赋值给 HashedFile 对象的 hash 字段。
组合哈希
尽管有了单个文件的哈希值,但我们仍不知道如何得到最终的哈希。幸运的是,曙光就在眼前。
下一步是确保我们有可复现的结果。 HashedFile 对象被存储在一个数组中,但文件系统遍历算法可能会改变,所以我们需要对那个数组进行排序。
| |
最后,我们到达了将所有这些哈希组合成一个的地方:
| |
在这里我们看到所有计算出的哈希被一个接一个地输入到一个新的哈希器中。在 computeHash 的最后,我们返回 hasher.finalResult(),现在我们明白哈希值是如何获得的了。
最终多哈希值
现在我们有了一个 SHA256 摘要,可以最终返回到 main.zig,在那里我们调用 Package.Manifest.hexDigest(fetch.actual_hash)。在那里,我们将多哈希头写入缓冲区,之后是我们的组合摘要。
顺便说一下,我们看到所有哈希头都是 1220 并非巧合。这是因为 Zig 硬编码了 SHA256 - 0x12,它有 32 字节的摘要 - 0x20。
总结
总结一下:最终哈希值是一个多哈希头 + SHA256 摘要。
这些摘要是包文件里的部分文件的 SHA256 摘要。这些摘要根据文件路径排序,并且对于普通文件和符号链接的计算方式不同。
这整个调查实际上是我尝试编写一个输出与 Zig 相同哈希的 shell 脚本的结果。如果你感兴趣,可以在这里阅读它:https://gist.github.com/michalsieron/a07da4216d6c5e69b32f2993c61af1b7。
在实验这个之后,我有一个想法,我很惊讶 Zig 没有检查 build.zig.zon 中列出的所有文件是否存在。但这可能是另一天的话题了。
译者注
在使用本地包时,可以使用下面的命令进行 hash 问题的排查:
| |
此外,社区已经有人把 multihash 的算法实现独立成一个单独的包,便于计算一个包的 hash 值:
通过 Zig,学习 C++ 元编程
尽管 Zig 社区宣称 Zig 语言是一个更好的 C (better C),但是我个人在学习 Zig 语言时经常会“触类旁通”C++。在这里列举一些例子来说明我的一些体会,可能会有一些不正确的地方,欢迎批评指正。
“元能力” vs “元类型”
在我看来,C++的增强方式是希望赋予语言一种“元能力”,能够让人重新发明新的类型,使得使用 C++的程序员使用自定义的类型,进行一种类似于“领域内语言”(DSL)编程。一个通常的说法就是 C++中任何类型定义都像是在模仿基本类型int。比如我们有一种类型 T,那么我们则需要定义 T 在以下几种使用场景的行为:
| |
通过定义各种行为,程序员可以用 C++去模拟基础类型int,自定义的创造新类型。但是 Zig 却采取了另一条路,这里我觉得 Zig 的取舍挺有意思,即它剥夺了程序员定义新类型的能力,只遵循 C 的思路,即struct就是struct,他和int就是不一样的,没有必要通过各种运算符重载来制造一种“幻觉”,模拟int。相反,Zig 吸收现代语言中最有用的“元类型”,比如slice,tuple,tagged union等作为语言内置的基本类型,从这一点上对 C 进行增强。虽然这样降低了语言的表现力,但是却简化了设计,降低了“心智负担”。
比如 Zig 里的tuple,C++里也有std::tuple。当然,std::tuple是通过一系列的模板元编程的方式实现的,但是这个在 Zig 里是内置的,因此写代码时出现语法错误,Zig 可以直接告诉你是tuple用的不对,但是 C++则会打印很多错误日志。再比如optional,C++里也有std::optinonal<T>,Zig 里只用?T。C++里有std::variant,而 Zig 里有tagged union。当然我们可以说,C++因为具备了这种元能力,当语法不足够“甜”时,我们可以发明新的轮子,但是代价就是系统愈发的复杂。而 Zig 则持续保持简单。
不过话说回来,很多底层系统的开发需求往往和这种类型系统的构建相悖,比如如果你的类型就是一个int的封装,那么即使发生拷贝你也无所谓性能开销。但是如果是一个struct,那么通常情况下,你会比较 care 拷贝,而可能考虑“移动”之类的手段。这个时候各种 C++的提供的幻觉,就成了程序员开发的绊脚石,经常你需要分析一段 C++表达式里到底有没有发生拷贝,他是左值还是右值,其实你在写 C 语言的时候也很少去考虑了这些,你在 Zig 里同样也不需要。
类型系统
C 语言最大弊病就是没有提供标准库,C++的标准库你要是能看懂,得具备相当的 C++的语法知识,但是 Zig 的标准库几乎不需要文档就能看懂。这其实是因为,在 C++里,类型不是一等成员(first class member),因此实现一些模版元编程算法特别不直观。但是在 Zig 里,type就是一等成员,比如你可以写:
| |
即,把一个type当成一个变量使用。但是 C++里如何来实现这一行代码呢?其实是如下:
| |
那么我们如果要对某个类型做个计算,比如组合一个新类型,Zig 里其实非常直观
| |
即输入一个类型,输出一个新类型,那么 C++里对应的东西是啥呢?
| |
相比之下, Zig 直观太多。那么很自然的,计算一个类型,Zig 里就是调用函数,而 C++则是模板类实例化,然后访问类成员。
| |
相当于对于 InputType 调用一个 Some“函数”,然后输出一个 OutputType。
命令式 VS 声明式
比如实现一个函数,输入一个 bool 值,根据 bool 值,如果为真,那么输出 type A,如果为假那么输出 type B。
| |
从这里 C++代码可以感觉出,其实你是拿着尺子,对照着基础模式,然后通过模版偏特化来实现不同分支的逻辑。
| |
这段代码表面上看是声明了一个类型 OutputType,而这个类型的生成依赖于一些条件。而这些条件就是模板元编程,用来从 A 和 B 中选择类型大小更大的类型,如果想要表达更复杂的逻辑,则需要掌握更多模板的奇技淫巧。
如果用 Zig 来做,则要简单的多:
| |
这段代码和普通的 CRUD 逻辑没什么区别,特殊的地方在于操作的对象是『类型』。
我们再来看递归的列子。比如有一个类型的 list,我们需要返回其中第 N 个 type。同样,由于在 C++中,类型不是一等成员,因此我们不可能有一个vector<type>的东东。那怎么办呢?方法就是直接把type list放在模板的参数列表里:typename ...T。
于是,我们写出“函数原型”:
| |
然后我们递归的基础情况
| |
然后写递归式,
| |
这个地方其实稍微有点难理解,其实就是拿着...T来模式匹配Head, ...Tail。
第一个偏特化,如果用命令式,类似于,
| |
第二个偏特化,类似于
| |
这里利用的其实是继承,让模板推导一路继承下去,如果 Index 不等于 0,那么Fn<Index, ...>类其实是空类,即,我们无法继承到using Output = ...的这个Output。但是 index 总会等于 0,那么到了等于 0 的那天,递归就终止了,因为,我们不需要继续 Index - 1 下去了,编译器会选择特化好的Fn<0, T,Tail...>这个特化,而不会选择继续递归。
但是 Zig 实现这个也很直观,由于slice和type都是内置的,我们可以直接:
| |
即这个也是完全命令式的。当然 C++20 之后也出现了if constexpr和concept来进一步简化模版元编程,C++的元编程也在向命令式的方向进化。
结束语
尽管 Zig 目前“还不成熟”,但是学习 Zig,如果采用一种对照的思路,偶尔也会“触类旁通”C++,达到举一反三的效果。
如何发布 Zig 应用程序
- 原文链接: https://zig.news/kristoff/how-to-release-your-zig-applications-2h90
- API 适配到 Zig 0.12.0 版本
- 本文配套代码在这里找到
你刚用 Zig 写了一个应用程序,并希望其他人使用它。 让用户方便使用的一种方式是为他们提供应用程序的预构建可执行文件。 接下来,我将讨论一个好的发版流程所需要正确处理的两个主要事项。
为什么提供预构建的可执行文件?
鉴于 C/C++ 依赖系统如何工作(或者说 不工作),对于某些 C/C++ 项目来说,
提供预编译好的的可执行文件几乎是必须的,
否则,普通人将陷入构建系统和配置系统的泥潭,
而这些系统的数量还要乘以项目的依赖数量。
使用 Zig 的话就不应该这样,因为 Zig 构建系统(加上即将推出的 Zig 包管理器)将能够处理一切,这意味着大多数编写良好的应用程序应该只需运行 zig build 即可成功构建。
话虽如此,你的应用程序越受欢迎,用户就越不关心它是用哪种语言编写的。 你的用户不想安装 Zig 并运行构建过程就能轻松使用应用程序(99%的情况下,稍后会讲到剩下的 1%), 因此最好还是预先构建你的应用程序。
zig build vs zig build-exe
在本文中,我们将看到如何为 Zig 项目制作、发布构建, 因此值得花一点时间来完全理解 Zig 构建系统和命令行之间的关系。
如果你有一个非常简单的 Zig 应用程序(例如,单个文件,无任何依赖),
构建项目最简单的方式是使用 zig build-exe myapp.zig,
这会在当前路径下创建一个可执行文件。
随着项目的增长,特别是开始有依赖之后,你可能想添加一个 build.zig 文件,
并开始用到 Zig 构建系统。一旦你开始这么做,你就可以完全控制命令行参数来影响构建过程。
你可以使用 zig init-exe 来了解基线 build.zig 文件的样子。
请注意,文件中的每一行代码都是显示定义,从而影响 zig build 子命令的行为。
最后一点需要注意的是,尽管使用 zig build 和 zig build-exe 时命令行参数会有所不同,
但在构建 Zig 代码方面,两者是等价的。更具体地说,尽管 Zig 构建可以调用任意命令,
并做其他可能根本与 Zig 代码无关的事情,但在构建 Zig 代码方面,
zig build 所做的一切就是为 build-exe 准备命令行参数。
这意味着,在编译 Zig 代码方面,zig build(假定 build.zig 中的代码是正确的)
和 zig build-exe 之间是一一对应关系。唯一的区别只是便利性。
构建模式
使用 zig build 或 zig build-exe myapp.zig 构建一个 Zig 项目时,
默认得到是一个调试构建的可执行文件。调试构建主要是为了开发方便,因而,通常被认为不适合发版。
调试构建旨在牺牲运行性能(运行更慢)来提高构建速度(编译更快),
不久, Zig 编译器将通过引入增量编译和就地二进制补丁(in-place binary patching)
来让这种权衡变得更加明显。
Zig 目前有三种主要的发版构建模式:ReleaseSafe、ReleaseFast 和 ReleaseSmall。
ReleaseSafe 应被视为发版时使用的主要模式:尽管使用了优化,
但仍保留了某些安全检查(例如,溢出和数组越界),
在发布处理不可控输入源(如互联网)的软件时,这些开销是绝对值得的。
ReleaseFast 旨在用于性能是主要关注点的软件,
例如视频游戏。这种构建模式不仅禁用了上述安全检查,
而且为了进行更激进的优化,它还假设代码中不存在这类编程错误。
ReleaseSmall 类似于 ReleaseFast(即,没有安全检查),
但它不是优先考虑性能,而是尝试最小化可执行文件大小。
例如,这是一种对于 WebAssembly 来说非常有意义的构建模式,
因为你希望可执行文件尽可能小,而沙箱运行环境已经提供了很多安全保障。
如何设置构建模式
使用 zig build-exe 时,你可以添加 -O ReleaseSafe
(或 ReleaseFast,或 ReleaseSmall)以获得相应的构建模式。
使用 zig build 时,取决于构建脚本的配置。默认构建脚本将包含以下代码行:
| |
这是你在命令行中指定发布模式的方式:zig build -Doptimize=ReleaseSafe(或
-Doptimize=ReleaseFast,或 -Doptimize=ReleaseSmall)。
选择正确的构建目标
现在,我们已经选择了正确的发版模式,是时候考虑构建目标了。 显而易见,如果使用的平台和构建平台不相同时,需要指定相应的构建目标, 但即使只打算为同一平台发版,也还是需要注意。
为了方便起见,假定你用的是 Windows 10,并试图为使用 Windows 10 的朋友构建可执行文件。
最想当然的方式是直接调用 zig build 或 zig build-exe(参见前文关于两个命令之间的差异与相似之处),然后将生成的可执行文件发送给你的朋友。
如果这样做,有时它会工作,但有时它会因非法指令(或类似错误)而崩溃。这到底发生了什么?
CPU 特性
在构建时如果不指定构建目标,Zig 将面向当前的机器进行构建优化, 这意味着将利用当前 CPU 支持的所有指令集。如果 CPU 支持 AVX 扩展, 那么 Zig 将使用它来执行 SIMD 操作。但不幸的是, 这也意味着,如果你朋友的 CPU 没有 AVX 扩展,那么应用程序将崩溃, 因为这个可执行文件确实包含非法指令。
解决这个问题最简单的方法是:始终在进行发布时指定一个构建目标。
没错,如果你指定你想要为 x86-64-linux 构建,
Zig 将设定一个与该系列所有 CPU 完全兼容的基线 CPU。
如果你想微调指令集的选择,你可以查看 zig build 的 -Dcpu 和 zig build-exe 的
-mcpu。我不会在这篇文章中更多地涉及这些细节。
实操中,下面的命令行将是你为 Arm macOS 发版时会用到的构建命令:
| |
请注意,目前在使用 zig build 时 = 是必需的,
而在使用 build-exe 时它不起作用(即你必须在 -target 及其值之间放一个空格)。
希望这些怪异的地方在不久将来会得到清理。
其它一些相关的构建目标:
| |
你可以通过调用 zig targets 看到 Zig 支持的目标 CPU 和
操作系统(以及 libc 和指令集)的完整列表。温馨提示:这是一个很长的列表。
最后,别忘了 build.zig 里的一切都必须明确定义,因此目标选项可以通过以下几行代码设置:
| |
这也意味着如果你想添加其他限制或以某种方式改变构建时应该如何指定目标, 你可以通过添加自己的代码来实现。
结束语
现在你已经了解了在进行发布构建时需要确保正确的事项:选择一个发布优化模式并选择正确的构建目标, 包括为你正在构建的同一系统进行发版构建。
这最后一点的一个有趣含义是,对于你的一些用户(通常情况下为 1%,乐观估计), 从头开始构建程序实际上更为可取,以确保他们充分利用其 CPU 的能力。
zig 构建系统解析 - 第三部分
- 原文链接: https://zig.news/xq/zig-build-explained-part-3-1ima
- API 适配到 Zig 0.11.0 版本
从现在起,我将只提供一个最精简的 build.zig,用来说明解决一个问题所需的步骤。如果你想了解如何将所有这些文件粘合到一个构建文件中,请阅读本系列第一篇文章。
复合项目
有很多简单的项目只包含一个可执行文件。但是,一旦开始编写库,就必须对其进行测试,通常会编写一个或多个示例应用程序。当人们开始使用外部软件包、C 语言库、生成代码等时,复杂性也会随之上升。
本文试图涵盖所有这些用例,并将解释如何使用 build.zig 来编写多个程序和库。
软件包
译者:此处代码和说明,需要 zig build-exe –pkg-begin,但是在 0.11 已经失效。所以删除。
库
但 Zig 也知道库这个词。但我们不是已经讨论过外部库了吗?
在 Zig 的世界里,库是一个预编译的静态或动态库,就像在 C/C++ 的世界里一样。库通常包含头文件(.h 或 .zig)和二进制文件(通常为 .a、.lib、.so 或 .dll)。
这种库的常见例子是 zlib 或 SDL。
与软件包相反,链接库的方式有两种
- (静态库)在命令行中传递文件名
- (动态库)使用 -L 将库的文件夹添加到搜索路径中,然后使用 -l 进行实际链接。
在 Zig 中,我们需要导入库的头文件,如果头文件在 Zig 中,则使用包,如果是 C 语言头文件,则使用 @cImport。
工具
如果我们的项目越来越多,那么在构建过程中就需要使用工具。这些工具通常会完成以下任务:
生成一些代码(如解析器生成器、序列化器或库头文件) 捆绑应用程序(例如生成 APK、捆绑应用程序……)。 创建资产包 … 有了 Zig,我们不仅能在构建过程中利用现有工具,还能为当前主机编译我们自己(甚至外部)的工具并运行它们。
但我们如何在 build.zig 中完成这些工作呢?
添加软件包
添加软件包通常使用 LibExeObjStep 上的 addPackage 函数。该函数使用一个 std.build.Pkg 结构来描述软件包的外观:
| |
我们可以看到,它有 2 个成员:
source_file 是定义软件包根文件的 FileSource。这通常只是指向文件的路径,如 vendor/zig-args/args.zig dependencies 是该软件包所需的可选软件包片段。如果我们使用更复杂的软件包,这通常是必需的。
这是个人建议:我通常会在 build.zig 的顶部创建一个名为 pkgs 的结构/名称空间,看起来有点像这样:
| |
随后通过编译步骤 exe,把模块加入进来。函数 addModule 的第一个参数 name 是模块名称
| |
添加库
添加库相对容易,但我们需要配置更多的路径。
注:在上一篇文章中,我们已经介绍了大部分内容,但现在还是让我们快速复习一遍:
假设我们要将 libcurl 链接到我们的项目,因为我们要下载一些文件。
系统库
对于 unixoid 系统,我们通常可以使用系统软件包管理器来链接系统库。方法是调用 linkSystemLibrary,它会使用 pkg-config 自行找出所有路径:
| |
对于 Linux 系统,这是链接外部库的首选方式。
本地库
不过,您也可以链接您作为二进制文件提供商的库。为此,我们需要调用几个函数。首先,让我们来看看这样一个库是什么样子的:
| |
我们可以看到,vendor/libcurl/include 路径包含我们的头文件,vendor/libcurl/lib 文件夹包含一个静态库(libcurl.a)和一个共享/动态库(libcurl.so)。
动态链接
要链接 libcurl,我们需要先添加 include 路径,然后向 zig 提供库的前缀和库名:(todo 代码有待验证,因为 curl 可能需要自己编译自己生成 static lib)
| |
addIncludePath 将文件夹添加到搜索路径中,这样 Zig 就能找到 curl/curl.h 文件。注意,我们也可以在这里传递 “vendor/libcurl/include/curl”,但你通常应该检查一下你的库到底想要什么。
addLibraryPath 对库文件也有同样的作用。这意味着 Zig 现在也会搜索 “vendor/libcurl/lib “文件夹中的库。
最后,linkSystemLibrary 会告诉 Zig 搜索名为 “curl “的库。如果你留心观察,就会发现上面列表中的文件名是 libcurl.so,而不是 curl.so。在 unixoid 系统中,库文件的前缀通常是 lib,这样就不会将其传递给系统。在 Windows 系统中,库文件的名字应该是 curl.lib 或类似的名字。
静态链接
当我们要静态链接一个库时,我们必须采取一些不同的方法:
| |
对 addIncludeDir 的调用没有改变,但我们突然不再调用带 link 的函数了?你可能已经知道了: 静态库实际上就是对象文件的集合。在 Windows 上,这一点也很相似,据说 MSVC 也使用了相同的工具集。
因此,静态库就像对象文件一样,通过 addObjectFile 传递给链接器,并由其解包。
注意:大多数静态库都有一些传递依赖关系。在我编译 libcurl 的例子中,就有 nghttp2、zstd、z 和 pthread,我们需要再次手动链接它们:
| |
我们可以继续静态链接越来越多的库,并拉入完整的依赖关系树。
通过源代码链接库
不过,我们还有一种与 Zig 工具链截然不同的链接库方式:
我们可以自己编译它们!
这样做的好处是,我们可以更容易地交叉编译我们的程序。为此,我们需要将库的构建文件转换成我们的 build.zig。这通常需要对 build.zig 和你的库所使用的构建系统都有很好的了解。但让我们假设这个库是超级简单的,只是由一堆 C 文件组成:
| |
这样,我们就可以使用 addSharedLibrary 和 addStaticLibrary 向 LibExeObjStep 添加库。
这一点尤其方便,因为我们可以使用 setTarget 和 setBuildMode 从任何地方编译到任何地方。
使用工具
在工作流程中使用工具,通常是在需要以 bison、flex、protobuf 或其他形式进行预编译时。工具的其他用例包括将输出文件转换为不同格式(如固件映像)或捆绑最终应用程序。
系统工具 使用预装的系统工具非常简单,只需使用 addSystemCommand 创建一个新步骤即可:
| |
从这里可以看出,我们只是向 addSystemCommand 传递了一个选项数组,该数组将反映我们的命令行调用。然后,我们按照习惯创建可执行文件,并使用 dependOn 在 cmd 上添加步骤依赖关系。
我们也可以反其道而行之,在编译程序时添加有关程序的小信息:
| |
size 是一个很好的工具,它可以输出有关可执行文件代码大小的信息,可能如下所示:
文本 数据 BSS Dec 十六进制 文件名 12377 620 104 13101 332d …
如您所见,我们在这里使用了 addArtifactArg,因为 addSystemCommand 只会返回一个 std.build.RunStep。这样,我们就可以增量构建完整的命令行,包括任何 LibExeObjStep 输出、FileSource 或逐字参数。
全新工具
最酷的是 我们还可以从 LibExeObjStep 获取 std.build.RunStep:
| |
此构建脚本将首先编译一个名为 pack 的可执行文件。然后将以我们的游戏和 assets.zig 文件作为命令行参数调用该可执行文件。
调用 zig build pack 时,我们将运行 tools/pack.zig。这很酷,因为我们还可以从头开始编译所需的工具。为了获得最佳的开发体验,你甚至可以从源代码编译像 bison 这样的 “外部 “工具,这样就不会依赖系统了!
将所有内容放在一起
一开始,所有这些都会让人望而生畏,但如果我们看一个更大的 build.zig 实例,就会发现一个好的构建文件结构会给我们带来很大帮助。
下面的编译脚本将编译一个虚构的工具,它可以通过 flex 生成的词法器解析输入文件,然后使用 curl 连接到服务器,并在那里传送一些文件。当我们调用 zig build deploy 时,项目将被打包成一个 zip 文件。正常的 zig 编译调用只会准备一个未打包的本地调试安装。
| |
如你所见,代码量很大,但通过使用块,我们可以将构建脚本结构化为逻辑组。
如果你想知道为什么我们不为 deploy_tool 和 test_suite 设置目标: 两者都是为了在主机平台上运行,而不是在目标机器上。 此外,deploy_tool 还设置了固定的编译模式,因为我们希望快速编译,即使我们编译的是应用程序的调试版本。
总结
看完这一大堆文字,你现在应该可以构建任何你想要的项目了。我们已经学会了如何编译 Zig 应用程序,如何为其添加任何类型的外部库,甚至如何为发布管理对应用程序进行后处理。
我们还可以通过少量的工作来构建 C 和 C++ 项目,并将它们部署到各个地方,而不仅仅是 Zig 项目。
即使我们混合使用项目、工具和其他一切。一个 build.zig 文件就能满足我们的需求。但很快你就会发现… 编译文件很快就会重复,而且有些软件包或库需要大量代码才能正确设置。
在下一篇文章中,我们将学习如何将 build.zig 文件模块化,如何为 Zig 创建方便的 sdks,甚至如何创建自己的构建步骤!
一如既往,继续黑客之旅!
zig 构建系统解析 - 第二部分
- 原文链接: https://zig.news/xq/zig-build-explained-part-2-1850
- API 适配到 Zig 0.11.0 版本
注释
从现在起,我将只提供一个最精简的 build.zig,用来说明解决一个问题所需的步骤。如果你想了解如何将所有这些文件粘合到一个构建文件中,请阅读本系列第一篇文章。
在命令行上编译 C 代码
Zig 有两种编译 C 代码的方法,而且这两种很容易混淆。
使用 zig cc
Zig 提供了 LLVM c 编译器 clang。第一种是 zig cc 或 zig c++,它是与 clang 接近 1:1 的前端。由于我们无法直接从 build.zig 访问这些功能(而且我们也不需要!),所以我将在快速的介绍这个主题。
如前所述,zig cc 是暴露的 clang 前端。您可以直接将 CC 变量设置为 zig cc,并使用 zig cc 代替 gcc 或 clang 来使用 Makefiles、CMake 或其他编译系统,这样您就可以在已有的项目中使用 Zig 的完整交叉编译体验。请注意,这只是理论上的说法,因为很多编译系统无法处理编译器名称中的空格。解决这一问题的办法是使用一个简单的封装脚本或工具,将所有参数转发给 zig cc。
假设我们有一个由 main.c 和 buffer.c 生成的项目,我们可以用下面的命令行来构建它:
| |
这将为我们创建一个名为 example 的可执行文件(在 Windows 系统中,应使用 example.exe 代替 example)。与普通的 clang 不同,Zig 默认会插入一个 -fsanitize=undefined,它将捕捉你使用的未定义行为。
如果不想使用,则必须通过 -fno-sanitize=undefined 或使用优化的发布模式(如 -O2)。
使用 zig cc 进行交叉编译与使用 Zig 本身一样简单:
| |
如你所见,只需向 -target 传递目标三元组,就能调用交叉编译。只需确保所有外部库都已准备好进行交叉编译即可!
使用 zig build-exe 和其他工具
使用 Zig 工具链构建 C 项目的另一种方法与构建 Zig 项目的方法相同:
| |
这里的主要区别在于,必须明确传递 -lc 才能链接到 libc,而且可执行文件的名称将从传递的第一个文件中推导出。如果想使用不同的可执行文件名,可通过 –name example 再次获取示例文件。
交叉编译也是如此,只需通过 -target x86_64-windows-gnu 或其他目标三元组即可:
| |
你会发现,使用这条编译命令,Zig 会自动在输出文件中附加 .exe 扩展名,并生成 .pdb 调试数据库。如果你在此处传递 –name example,输出文件也会有正确的 .exe 扩展名,所以你不必考虑这个问题。
用 build.zig 创建 C 代码
那么,我们如何用 build.zig 来构建上面的两个示例呢?
首先,我们需要创建一个新的编译目标:
| |
然后,我们通过 addCSourceFile 添加两个 C 语言文件:
| |
第一个参数 addCSourceFile 是要添加的 C 或 C++ 文件的名称,第二个参数是该文件要使用的命令行选项列表。
请注意,我们向 addExecutable 传递的是空值,因为我们没有要编译的 Zig 源文件。
现在,调用 zig build 可以正常运行,并在 zig-out/bin 中生成一个可执行文件。很好,我们用 Zig 构建了第一个小 C 项目!
如果你想跳过检查 C 代码中的未定义行为,就必须在调用时添加选项:
| |
使用外部库
通常情况下,C 项目依赖于其他库,这些库通常预装在 Unix 系统中,或通过软件包管理器提供。
为了演示这一点,我们创建一个小工具,通过 curl 库下载文件,并将文件内容打印到标准输出:
| |
要编译这个程序,我们需要向编译器提供正确的参数,包括包含路径、库和其他参数。幸运的是,我们可以使用 Zig 内置的 pkg-config 集成:
| |
让我们创建程序,并通过 URL 调用它
| |
配置路径
由于我们不能在交叉编译项目中使用 pkg-config,或者我们想使用预编译的专用库(如 BASS 音频库),因此我们需要配置包含路径和库路径。
这可以通过函数 addIncludePath 和 addLibraryPath 来完成:
| |
addIncludePath 和 addLibraryPath 都可以被多次调用,以向编译器添加多个路径。这些函数不仅会影响 C 代码,还会影响 Zig 代码,因此 @cImport 可以访问包含路径中的所有头文件。
每个文件的包含路径
因此,如果我们需要为每个 C 文件设置不同的包含路径,我们就需要用不同的方法来解决这个问题: 由于我们仍然可以通过 addCSourceFile 传递任何 C 编译器标志,因此我们也可以在这里手动设置包含目录。
| |
上面的示例非常简单,所以你可能会想为什么需要这样的东西。答案是,有些库的头文件名称非常通用,如 api.h 或 buffer.h,而您希望使用两个共享头文件名称的不同库。
构建 C++ 项目
到目前为止,我们只介绍了 C 文件,但构建 C++ 项目并不难。你仍然可以使用 addCSourceFile,但只需传递一个具有典型 C++ 文件扩展名的文件,如 cpp、cxx、c++ 或 cc:
| |
如你所见,我们还需要调用 linkLibCpp,它将链接 Zig 附带的 c++ 标准库。
这就是构建 C++ 文件所需的全部知识,没有什么更神奇的了。
指定语言版本
试想一下,如果你创建了一个庞大的项目,其中的 C 或 C++ 文件有新有旧,而且可能是用不同的语言标准编写的。为此,我们可以使用编译器标志来传递 -std=c90 或 -std=c++98:
| |
条件编译
与 Zig 相比,C 和 C++ 的条件编译方式非常繁琐。由于缺乏惰性求值的功能,有时必须根据目标环境来包含/排除文件。你还必须提供宏定义来启用/禁用某些项目功能。
Zig 编译系统可以轻松处理这两种变体:
| |
通过 defineCMacro,我们可以定义自己的宏,就像使用 -D 编译器标志传递宏一样。第一个参数是宏名,第二个值是一个可选项,如果不为空,将设置宏的值。
有条件地包含文件就像使用 if 一样简单,你可以这样做。只要不根据你想在构建脚本中定义的任何约束条件调用 addCSourceFile 即可。只包含特定平台的文件?看看上面的脚本就知道了。根据系统时间包含文件?也许这不是个好主意,但还是有可能的!
编译大型项目
由于大多数 C(更糟糕的是 C++)项目都有大量文件(SDL2 有 411 个 C 文件和 40 个 C++ 文件),我们必须找到一种更简单的方法来编译它们。调用 addCSourceFile 400 次并不能很好地扩展。
因此,我们可以做的第一个优化就是将 c 和 c++ 标志放入各自的变量中:
| |
这样就可以在项目的不同组件和不同语言之间轻松共享标志。
addCSourceFile 还有一个变种,叫做 addCSourceFiles。它使用的不是文件名,而是可编译的所有源文件的文件名片段。这样,我们就可以收集某个文件夹中的所有文件:
| |
正如您所看到的,我们可以轻松搜索某个文件夹中的所有文件,匹配文件名并将它们添加到源代码集合中。然后,我们只需为每个文件集调用一次 addCSourceFiles,就可以大展身手了。
你可以制定很好的规则来匹配 exe.target 和文件夹名称,以便只包含通用文件和适合你的平台的文件。不过,这项工作留给读者自己去完成。
注意:其他构建系统会考虑文件名,而 Zig 系统不会!例如,在一个 qmake 项目中不能有两个名为 data.c 的文件!Zig 并不在乎,你可以添加任意多的同名文件,只要确保它们在不同的文件夹中就可以了 😏。
编译 Objective C
我完全忘了!Zig 不仅支持编译 C 和 C++,还支持通过 clang 编译 Objective C!
虽然不支持 C 或 C++,但至少在 macOS 上,你已经可以编译 Objective C 程序并添加框架了:
| |
在这里,链接 libc 是隐式的,因为添加框架会自动强制链接 libc。是不是很酷?
混合使用 C 和 Zig 源代码
现在,是最后一章: 混合 C 代码和 Zig 代码!
为此,我们只需将 addExecutable 中的第二个参数设置为文件名,然后点击编译!
| |
这就是需要做的一切!是这样吗?
实际上,有一种情况现在还没有得到很好的支持: 您应用程序的入口点现在必须在 Zig 代码中,因为根文件必须导出一个 pub fn main(…) ……。 因此,如果你想将 C 项目中的代码移植到 Zig 中,你必须将 argc 和 argv 转发到你的 C 代码中,并将 C 代码中的 main 重命名为其他函数(例如 oldMain),然后在 Zig 中调用它。如果需要 argc 和 argv,可以通过 std.process.argsAlloc 获取。或者更好: 在 Zig 中重写你的入口点,然后从你的项目中移除一些 C 语言!
结论
假设你只编译一个输出文件,那么现在你应该可以将几乎所有的 C/C++ 项目移植到 build.zig。
如果你需要一个以上的构建工件,例如共享库和可执行文件,你应该阅读下一篇文章,它将介绍如何在一个 build.zig 中组合多个项目,以创建便捷的构建体验。
敬请期待!
zig 构建系统解析 - 第一部分
- 原文链接: https://zig.news/xq/zig-build-explained-part-1-59lf
- API 适配到 Zig 0.11.0 版本
Zig 构建系统仍然缺少文档,对很多人来说,这是不使用它的致命理由。还有一些人经常寻找构建项目的秘诀,但也在与构建系统作斗争。
本系列试图深入介绍构建系统及其使用方法。
我们将从一个刚刚初始化的 Zig 项目开始,逐步深入到更复杂的项目。在此过程中,我们将学习如何使用库和软件包、添加 C 代码,甚至如何创建自己的构建步骤。
免责声明
由于我不会解释 Zig 语言的语法或语义,因此我希望你至少已经有了一些使用 Zig 的基本经验。我还将链接到标准库源代码中的几个要点,以便您了解所有这些内容的来源。我建议你阅读编译系统的源代码,因为如果你开始挖掘编译脚本中的函数,大部分内容都不言自明。所有功能都是在标准库中实现的,不存在隐藏的构建魔法。
开始
我们通过新建一个文件夹来创建一个新项目,并在该文件夹中调用 zig init-exe。
这将生成如下 build.zig 文件(我去掉了注释)
| |
基础知识
构建系统的核心理念是,Zig 工具链将编译一个 Zig 程序 (build.zig),该程序将导出一个特殊的入口点(pub fn build(b: *std.build.Builder) void),当我们调用 zig build 时,该入口点将被调用。
然后,该函数将创建一个由 std.build.Step 节点组成的有向无环图,其中每个步骤都将执行构建过程的一部分。
每个步骤都有一组依赖关系,这些依赖关系需要在步骤本身完成之前完成。作为用户,我们可以通过调用 zig build ${step-name} 来调用某些已命名的步骤,或者使用其中一个预定义的步骤(例如 install)。
要创建这样一个步骤,我们需要调用 Builder.step
| |
这将为我们创建一个新的步骤 step-name,当我们调用 zig build --help 时将显示该步骤:
| |
请注意,除了在 zig build –help 中添加一个小条目并允许我们调用 zig build step-name 之外,这个步骤仍然没有任何作用。
Step 遵循与 std.mem.Allocator 相同的接口模式,需要实现一个 make 函数。步骤创建时将调用该函数。对于我们在这里创建的步骤,该函数什么也不做。
现在,我们需要创建一个稍正式的 Zig 程序:
编译 Zig 源代码
要使用编译系统编译可执行文件,编译器需要使用函数 Builder.addExecutable,它将为我们创建一个新的 LibExeObjStep。这个步骤实现是 zig build-exe、zig build-lib、zig build-obj 或 zig test 的便捷封装,具体取决于初始化方式。本文稍后将对此进行详细介绍。
现在,让我们创建一个步骤来编译我们的 src/main.zig 文件(之前由 zig init-exe 创建)
| |
我们在这里添加了几行。首先,const exe = b.addExecutable 将创建一个新的 LibExeObjStep,将 src/main.zig 编译成一个名为 fresh 的文件(或 Windows 上的 fresh.exe)。
第二个添加的内容是 compile_step.dependOn(&exe.step);。这就是我们构建依赖关系图的方法,并声明当执行 compile_step 时,exe 步骤也需要执行。
你可以调用 zig build,然后再调用 zig build compile 来验证这一点。第一次调用不会做任何事情,但第二次调用会输出一些编译信息。
这将始终在当前机器的调试模式下编译,因此对于初学者来说,这可能就足够了。但如果你想开始发布你的项目,你可能需要启用交叉编译:
交叉编译
交叉编译是通过设置程序的目标和编译模式来实现的
| |
在这里,.optimize = .ReleaseSafe, 将向编译调用传递 -O ReleaseSafe。但是!LibExeObjStep.setTarget 需要一个 std.zig.CrossTarget 作为参数,而你通常希望这个参数是可配置的。
幸运的是,构建系统为此提供了两个方便的函数:
- Builder.standardReleaseOptions
- Builder.standardTargetOptions
使用这些函数,可以将编译模式和目标作为命令行选项:
| |
现在,如果你调用 zig build –help 命令,就会在输出中看到以下部分,而之前这部分是空的:
| |
前两个选项由 standardTargetOptions 添加,其他选项由 standardOptimizeOption 添加。现在,我们可以在调用构建脚本时使用这些选项:
| |
可以看到,对于布尔选项,我们可以省略 =true,直接设置选项本身。
但我们仍然必须调用 zig build 编译,因为默认调用仍然没有任何作用。让我们改变一下!
安装工件
要安装任何东西,我们必须让它依赖于构建器的安装步骤。该步骤是已创建的,可通过 Builder.getInstallStep() 访问。我们还需要创建一个新的 InstallArtifactStep,将我们的 exe 文件复制到安装目录(通常是 zig-out)
| |
这将做几件事:
- 创建一个新的 InstallArtifactStep,将 exe 的编译结果复制到 $prefix/bin 中。
- 由于 InstallArtifactStep(隐含地)依赖于 exe,因此它也将编译 exe
- 当我们调用 zig build install(或简称 zig build)时,它将创建 InstallArtifactStep。
- InstallArtifactStep 会将 exe 的输出文件注册到一个列表中,以便再次卸载它
现在,当你调用 zig build 时,你会看到一个新的目录 zig-out 被创建了.看起来有点像这样:
| |
现在运行 ./zig-out/bin/fresh,就能看到这条信息:
| |
或者,你也可以通过调用 zig build uninstall 再次卸载。这将删除 zig build install 创建的所有文件,但不会删除目录!
由于安装过程是一个非常普通的操作,它有快捷方法,以缩短代码。
| |
如果你在项目中内置了多个应用程序,你可能会想创建几个单独的安装步骤,并手动依赖它们,而不是直接调用 b.installArtifact(exe);,但通常这样做是正确的。
请注意,我们还可以使用 Builder.installFile(或其他,有很多变体)和 Builder.installDirectory 安装任何其他文件。
现在,从理解初始构建脚本到完全扩展,还缺少一个部分:
运行已构建的应用程序
为了开发用户体验和一般便利性,从构建脚本中直接运行程序是非常实用的。这通常是通过运行步骤实现的,可以通过 zig build run 调用。
为此,我们需要一个 RunStep,它将执行我们能在系统上运行的任何可执行文件
| |
RunStep 有几个函数可以为执行进程的 argv 添加值:
- addArg 将向 argv 添加一个字符串参数。
- addArgs 将同时添加多个字符串参数
- addArtifactArg 将向 argv 添加 LibExeObjStep 的结果文件
- addFileSourceArg 会将其他步骤生成的任何文件添加到 argv。
请注意,第一个参数必须是我们要运行的可执行文件的路径。在本例中,我们要运行 exe 的编译输出。
现在,当我们调用 zig build run 时,我们将看到与自己运行已安装的 exe 相同的输出:
| |
请注意,这里有一个重要的区别: 使用 RunStep 时,我们从 ./zig-cache/…/fresh 而不是 zig-out/bin/fresh 运行可执行文件!如果你加载的文件相对于可执行路径,这一点可能很重要。
RunStep 的配置非常灵活,可以通过 stdin 向进程传递数据,也可以通过 stdout 和 stderr 验证输出。你还可以更改工作目录或环境变量。
对了,还有一件事:
如果你想从 zig 编译命令行向进程传递参数,可以通过访问 Builder.args 来实现
| |
这样就可以在 cli 上的 – 后面传递参数:
| |
结论
本系列的第一章应该能让你完全理解本文开头的构建脚本,并能创建自己的构建脚本。
大多数项目甚至只需要编译、安装和运行一些 Zig 可执行文件,所以你就可以开始了!
下一部分我将介绍如何构建 C 和 C++ 项目。
Zig 多版本管理
由于 Zig 还在快速开发迭代中,因此项目很有可能出现新版本 Zig 无法编译的情况,这时候一方面可以跟踪上游进展,看看是否有 workaround,另一个就是使用固定的版本来开发这个项目,显然这种方式更靠谱一些,因此这篇文章就来介绍一些管理多个 Zig 版本的方式。
Zig version manager
现在 Zig 的版本管理工具主要有如下几个:
- marler8997/zigup
- Download and manage zig compilers
- tristanisham/zvm
- Lets you easily install/upgrade between different versions of Zig
- hendriknielaender/zvm
- Fast and simple zig version manager
他们工作方式类似,大致步骤:
- 从 index.json 解析所有版本,然后根据当前系统架构确定要安装的二进制,
- 创建一个类似
current软链用来表示当前的 Zig 安装目录, - 根据项目下
.zig-version文件中指定的版本,修改current软链的指向,保证PATH中的 Zig 版本是正确的
相关实现:
通用版本管理工具 asdf
鉴于社区之前的 asdf-zig 已经年久失修,zigcc 已经 fork 过来,对下载的软件包增加了 checksum 校验,防止出现中间人攻击,欢迎大家使用。
多版本管理是个常见的需求,比如 Python 中的 pyenv、Ruby 中的 rvm,甚至还有一个通用的框架:asdf,名字简单暴力,敲起来得心应手。安装方式可以参考官方文档的 Getting Started。
它们的工作原理也都比较类似,通过修改 Shell 中的环境变量实现。在执行具体命令(比如:python、zig)时,会拦截到一个中转的工具(学名叫 shims,翻译为“垫片”),由它来确定要执行的版本(比如项目根目录的 .python-version ),然后将实际参数派发过去。
社区也有 Zig 的插件,安装也比较简单:
| |
常用命令
| |
这里说明一点,可以使用 asdf install zig master 的方式来安装 master 分支的 Zig,但是由于 Zig 的 master 一直在变,因此本次安装的版本可以会滞后,一个简单的办法是先卸载,再重新安装。
如果想保留,可以手动把 master 目录改个名字,然后修改 zig 的 shims 让其识别到这个版本,之后就可以继续安装最新的 master 版本:
| |
上面的 0.12.0-dev.891+2254882eb 即是从 master 重命名出来的版本。下面这个脚本可以自动把 master 的版本固定下来:
| |
问题排查
asdf 现在不支持 verbose 选项,因此安装过程中如果卡在某个地方,没法排查。一般来说,主要是下载 tar 包慢了,毕竟这取决于网络环境,可以这么改一下 install 文件:
| |
这样就可以看到进度了:
| |
Zig音频之MIDI —— 源码解读
MIDI 是“乐器数字接口”的缩写,是一种用于音乐设备之间通信的协议。而 zig-midi 主要是在对 MIDI 的元数据、音频头等元数据进行一些处理的方法上进行了集成。
| |
基础
在 MIDI 协议中,0xFF 是一个特定的状态字节,用来表示元事件(Meta Event)的开始。元事件是 MIDI 文件结构中的一种特定消息,通常不用于实时音频播放,但它们包含有关 MIDI 序列的元数据,例如序列名称、版权信息、歌词、时间标记、速度(BPM)更改等。
以下是一些常见的元事件类型及其关联的 0xFF 后的字节:
0x00: 序列号 (Sequence Number)0x01: 文本事件 (Text Event)0x02: 版权通知 (Copyright Notice)0x03: 序列/曲目名称 (Sequence/Track Name)0x04: 乐器名称 (Instrument Name)0x05: 歌词 (Lyric)0x06: 标记 (Marker)0x07: 注释 (Cue Point)0x20: MIDI Channel Prefix0x21: End of Track (通常跟随值0x00,表示轨道的结束)0x2F: Set Tempo (设定速度,即每分钟的四分音符数)0x51: SMPTE Offset0x54: 拍号 (Time Signature)0x58: 调号 (Key Signature)0x59: Sequencer-Specific Meta-event
例如,当解析 MIDI 文件时,如果遇到字节 0xFF 0x03,那么接下来的字节将表示序列或曲目名称。
在实际的 MIDI 文件中,元事件的具体结构是这样的:
0xFF: 元事件状态字节。- 元事件类型字节,例如上面列出的
0x00,0x01等。 - 长度字节(或一系列字节),表示该事件数据的长度。
- 事件数据本身。
元事件主要存在于 MIDI 文件中,特别是在标准 MIDI 文件 (SMF) 的上下文中。在实时 MIDI 通信中,元事件通常不会被发送,因为它们通常不会影响音乐的实际播放。
Midi.zig
本文件主要是处理 MIDI 消息的模块,为处理 MIDI 消息提供了基础结构和函数。
| |
这定义了一个名为 Message 的公共结构,表示 MIDI 消息,为处理 MIDI 消息提供了基础结构和函数。它包含三个字段:状态、值和几个公共方法。
- kind 函数:根据 MIDI 消息的状态码确定消息的种类。
- channel 函数:根据消息的种类返回 MIDI 通道,如果消息不包含通道信息则返回 null。
- value 和 setValue 函数:用于获取和设置 MIDI 消息的值字段。
- Kind 枚举:定义了 MIDI 消息的所有可能种类,包括通道事件和系统事件。
midi 消息结构
我们需要先了解 MIDI 消息的一些背景。
在 MIDI 协议中,某些消息的值可以跨越两个 7 位的字节,这是因为 MIDI 协议不使用每个字节的最高位(这通常被称为状态位)。这意味着每个字节只使用它的低 7 位来携带数据。因此,当需要发送一个大于 7 位的值时(比如 14 位),它会被拆分成两个 7 位的字节。
setValue 这个函数做的事情是将一个 14 位的值(u14)拆分为两个 7 位的值,并将它们设置到 message.values 中。
以下是具体步骤的解释:
获取高 7 位:
v >> 7把 14 位的值右移 7 位,这样我们就得到了高 7 位的值。截断并转换:
@truncate(v >> 7)截断高 7 位的值,确保它是 7 位的。@as(u7, @truncate(v >> 7))确保这个值是u7类型,即一个 7 位的无符号整数。获取低 7 位:
@truncate(v)直接截断原始值,保留低 7 位。设置值:
message.values = .{ ... }将这两个 7 位的值设置到message.values中。
事件
针对事件,我们看 enum。
| |
这段代码定义了一个名为 Kind 的公共枚举类型(enum),它描述了 MIDI 中可能的事件种类。每个枚举成员都代表 MIDI 协议中的一个特定事件。这些事件分为两大类:频道事件(Channel events)和系统事件(System events)。
这个 Kind 枚举为处理 MIDI 消息提供了一个结构化的方法,使得在编程时可以清晰地引用特定的 MIDI 事件,而不是依赖于原始的数字或其他编码。
以下是对每个枚举成员的简要说明:
频道事件 (Channel events)
- NoteOff:这是一个音符结束事件,表示某个音符不再播放。
- NoteOn:这是一个音符开始事件,表示开始播放某个音符。
- PolyphonicKeyPressure:多声道键盘压力事件,表示对特定音符的压力或触摸敏感度的变化。
- ControlChange:控制变更事件,用于发送如音量、平衡等控制信号。
- ProgramChange:程序(音色)变更事件,用于改变乐器的音色。
- ChannelPressure:频道压力事件,与多声道键盘压力相似,但它适用于整个频道,而不是特定音符。
- PitchBendChange:音高弯曲变更事件,表示音符音高的上升或下降。
系统事件 (System events)
- ExclusiveStart:独占开始事件,标志着一个独占消息序列的开始。
- MidiTimeCodeQuarterFrame:MIDI 时间码四分之一帧,用于同步与其他设备。
- SongPositionPointer:歌曲位置指针,指示序列器的当前播放位置。
- SongSelect:歌曲选择事件,用于选择特定的歌曲或序列。
- TuneRequest:调音请求事件,指示设备应进行自我调音。
- ExclusiveEnd:独占结束事件,标志着一个独占消息序列的结束。
- TimingClock:计时时钟事件,用于节奏的同步。
- Start:开始事件,用于启动序列播放。
- Continue:继续事件,用于继续暂停的序列播放。
- Stop:停止事件,用于停止序列播放。
- ActiveSensing:活动感知事件,是一种心跳信号,表示设备仍然在线并工作。
- Reset:重置事件,用于将设备重置为其初始状态。
其他
- Undefined:未定义事件,可能表示一个未在此枚举中定义的或无效的 MIDI 事件。
decode.zig
本文件是对 MIDI 文件的解码器, 提供了一组工具,可以从不同的输入源解析 MIDI 文件的各个部分。这样可以方便地读取和处理 MIDI 文件。
| |
- statusByte: 解析 MIDI 消息的首个字节,来确定是否这是一个状态字节,还是一个数据字节。将一个字节 b 解码为一个 u7 类型的 MIDI 状态字节,如果字节 b 不是一个状态字节,则返回 null。换句话说,midi 的消息是 14 位,如果高 7 位不为空,则是 midi 消息的状态字节。在 MIDI 协议中,消息的首个字节通常是状态字节,但也可能用之前的状态字节(这称为“运行状态”)来解释接下来的字节。因此,这段代码需要确定它是否读取了一个新的状态字节,或者它是否应该使用前一个消息的状态字节。
- readDataByte: 从 reader 中读取并返回一个数据字节。如果读取的字节不符合数据字节的规定,则抛出 InvalidDataByte 错误。
- message: 从 reader 读取并解码一个 MIDI 消息。如果读取的字节不能形成一个有效的 MIDI 消息,则抛出 InvalidMessage 错误。这是一个复杂的函数,涉及到解析 MIDI 消息的不同种类。
- chunk,chunkFromBytes: 这两个函数从 reader 或直接从字节数组 bytes 中解析一个 MIDI 文件块头。
- fileHeader, fileHeaderFromBytes: 这两个函数从 reader 或直接从字节数组 bytes 中解析一个 MIDI 文件头。
- int: 从 reader 中解码一个可变长度的整数。
- metaEvent: 从 reader 中解析一个 MIDI 元事件。
- trackEvent: 从 reader 中解析一个 MIDI 轨道事件。它可以是 MIDI 消息或元事件。
- file: 用于从 reader 解码一个完整的 MIDI 文件。它首先解码文件头,然后解码所有的文件块。这个函数会返回一个表示 MIDI 文件的结构体。
message 解析
| |
这段代码的目的是确定 MIDI 消息的状态字节。它可以是从 reader 读取的当前字节,或者是从前一个 MIDI 消息中获取的。这样做是为了支持 MIDI 协议中的“运行状态”,在该协议中,连续的 MIDI 消息可能不会重复状态字节。
const status_byte = ...;: 这是一个常量声明。status_byte将保存 MIDI 消息的状态字节。if (statusByte(first_byte.?)) |status_byte| blk: { ... }:
statusByte(first_byte.?): 这是一个函数调用,它检查first_byte是否是一个有效的状态字节。.?是可选值的语法,它用于解包first_byte的值(它是一个可选的u8,可以是u8或null)。|status_byte|: 如果statusByte函数返回一个有效的状态字节,则这个值会被捕获并赋给这里的status_byte变量。blk:: 这是一个匿名代码块的标签。Zig 允许你给代码块命名,这样你可以从该代码块中跳出。{ ... }: 这是一个代码块。在这里,first_byte被设置为null,然后使用break :blk status_byte;来结束此代码块,并将status_byte的值赋给外部的status_byte常量。
else if (last_message) |m| blk: { ... }:
- 如果
first_byte不是一个状态字节,代码会检查是否存在一个名为last_message的前一个 MIDI 消息。 |m|: 如果last_message存在(即它不是null),它的值将被捕获并赋给m。{ ... }: 这是另一个代码块。在这里,它检查m是否有一个通道。如果没有,则返回一个InvalidMessage错误。否则,使用break :blk m.status;结束此代码块,并将m.status的值赋给外部的status_byte常量。
else return error.InvalidMessage;: 如果first_byte不是状态字节,并且不存在前一个消息,那么返回一个InvalidMessage错误。
encode.zig
本文件用于将 MIDI 数据结构编码为其对应的二进制形式。具体来说,它是将内存中的 MIDI 数据结构转换为 MIDI 文件格式的二进制数据。
| |
message 函数:这是将 MIDI 消息编码为字节序列的函数, 将单个 MIDI 消息编码为其二进制形式。根据消息类型,这会向提供的 writer 写入一个或多个字节。若消息需要状态字节,并且不同于前一个消息的状态,函数会写入状态字节。接着,根据消息的种类,函数会写入所需的数据字节。
chunkToBytes 函数:将 MIDI 文件的块(Chunk)信息转换为 8 字节的二进制数据。这 8 字节中包括 4 字节的块类型和 4 字节的块长度。它复制块类型到前 4 个字节,然后写入块的长度到后 4 个字节,并返回结果。
fileHeaderToBytes 函数:编码 MIDI 文件的头部为 14 字节的二进制数据。这 14 字节包括块信息、文件格式、轨道数量和时间划分信息。
int 函数:将一个整数编码为 MIDI 文件中的可变长度整数格式。在 MIDI 文件中,某些整数值使用一种特殊的编码格式,可以根据整数的大小变化长度。
metaEvent 函数:将 MIDI 元事件(Meta Event)编码为二进制数据, 这包括事件的类型和长度。具体则是编码一个元事件,首先写入其种类字节,然后是其长度。
trackEvent 函数:编码轨道事件。轨道事件可以是元事件或 MIDI 事件,函数首先写入事件之间的时间差(delta 时间),然后根据事件类型(MetaEvent 或 MidiEvent)编码事件内容。
file 函数:这是主函数,用于将整个 MIDI 文件数据结构编码为其二进制形式。它首先编码文件头,然后循环编码每个块和块中的事件。
int 函数
| |
这个函数int用于编码一个整数为 MIDI 文件中的可变长度整数格式。在 MIDI 文件中,许多值(如 delta 时间)使用这种可变长度编码。
详细地解析这个函数的每一步:
- 参数定义:
writer: 任意类型的写入对象,通常是一种流或缓冲区,可以向其写入数据。i: 一个最多 28 位的无符号整数(u28),即要编码的值。
- 局部变量初始化:
tmp:作为输入整数的临时副本。is_first:一个布尔值,用于指示当前处理的是否是整数的第一个字节。buf: 定义一个 4 字节的缓冲区。因为最大的u28值需要 4 个字节的可变长度编码。fbs:使用io.fixedBufferStream创建一个固定缓冲区的流,并获取它的写入器。
- 循环进行可变长度编码:
- 循环条件是:直到
tmp为 0 并且不是第一个字节。 : (is_first = false)是一个后置条件,每次循环结束后都会执行。(@as(u8, 1 << 7) * @intFromBool(!is_first))1 << 7: 这个操作是左移操作。数字 1 在二进制中表示为0000 0001。当你将它左移 7 位时,你得到1000 0000,这在十进制中等于128。@intFromBool(!is_first): 这是将上一步得到的布尔值转换为整数。在许多编程语言中,true 通常被视为 1,false 被视为 0。在 Zig 中,这种转换不是隐式的,所以需要用@intFromBool()函数来进行转换@as(u8, 1 << 7): 这里是将数字 128(从 1 « 7 得到)显式地转换为一个 8 位无符号整数。(@as(u8, 1 << 7) * @intFromBool(!is_first)): 将转换后的数字 128 与从布尔转换得到的整数(0 或 1)相乘。如果is_first为true(即这是第一个字节),那么整个表达式的值为 0。如果is_first为false(即这不是第一个字节),那么整个表达式的值为 128(1000 0000in 二进制)。- 这种结构在 MIDI 变长值的编码中很常见。MIDI 变长值的每个字节的最高位被用作“继续”位,指示是否有更多的字节跟随。如果最高位是 1,那么表示还有更多的字节;如果是 0,表示这是最后一个字节。
- 在每次迭代中,它提取
tmp的最后 7 位并将其编码为一个字节,最高位根据是否是第一个字节来设置(如果是第一个字节,则为 0,否则为 1)。 - 然后,整数右移 7 位,以处理下一个字节。
- 请注意,这种编码方式实际上是从低字节到高字节的反向方式,所以接下来需要翻转这些字节。
- 翻转字节:
- 使用
mem.reverse翻转在固定缓冲区流中编码的字节。这是因为我们是以反序编码它们的,现在我们要将它们放在正确的顺序。
- 写入结果:
- 使用提供的
writer将翻转后的字节写入到目标位置。
file.zig
主要目的是为了表示和处理 MIDI 文件的不同部分,以及提供了一个迭代器来遍历 MIDI 轨道的事件。
| |
- Header 结构:
- 表示 MIDI 文件的头部。
- 包含一个块、格式、轨道数以及除法。
- Chunk 结构:
- 表示 MIDI 文件中的块,每个块有一个种类和长度。
- 定义了文件头和轨道头的常量。
- MetaEvent 结构:
- 表示 MIDI 的元事件。
- 它有一个种类字节和长度。
- 有一个函数,根据种类字节返回事件的种类。
- 定义了所有可能的元事件种类。
- TrackEvent 结构:
- 表示 MIDI 轨道中的事件。
- 它有一个 delta 时间和种类。
- 事件种类可以是 MIDI 事件或元事件。
- File 结构:
- 表示整个 MIDI 文件。
- 它有格式、除法、头部数据和一系列块。
- 定义了一个子结构 FileChunk,用于表示文件块的种类和字节数据。
- 提供了一个清除方法来释放文件的资源。
- TrackIterator 结构:
- 是一个迭代器,用于遍历 MIDI 轨道的事件。
- 它使用一个 FixedBufferStream 来读取事件。
- 定义了一个 Result 结构来返回事件和关联的数据。
- 提供了一个
next方法来读取下一个事件。
Build.zig
buid.zig 是一个 Zig 构建脚本(build.zig),用于配置和驱动 Zig 的构建过程。
| |
这个 build 比较复杂,我们逐行来解析:
| |
- 使用 b.step()方法定义了一个名为 test 的步骤。描述是“在所有模式下运行所有测试”。
| |
- Zig 有几种构建模式,例如 Debug、ReleaseSafe 等, 上面则是为每种构建模式生成测试.
- 这里,@typeInfo()函数获取了一个类型的元信息。std.builtin.Mode 是 Zig 中定义的构建模式的枚举。Enum.fields 获取了这个枚举的所有字段。
| |
- 配置示例构建,为所有示例创建的构建步骤.
| |
- all_step 是一个汇总步骤,它依赖于之前定义的所有其他步骤。最后,b.default_step.dependOn(all_step);确保当你仅仅执行 zig build(没有指定步骤)时,all_step 会被执行。
Bog GC Design
Bog GC Design
Bog is a small scripting language developed using Zig. Its GC design is inspired by a paper titled An efficient of Non-Moving GC for Function languages.
Overview
- Introduction
- Design of the Heap
- Types of GC
- Design of Bitmap
- Implementation
Introduction
GC stands for garbage collection, which is primarily a memory management strategy for the heap region. Memory allocations in the heap are done in exponentially increasing sizes, with a special sub-heap dedicated solely to very large objects. One advantage of this approach might be its efficiency in handling memory requests of various sizes.
Represented as a formula:
$$ Heap = (M, S, (H_3, H_4, …, H_{12})) $$
Where:
- M: is a special region dedicated to storing large objects.
- S: represents the free space.
- H: is the sub-heap used for storing smaller objects. $H_i$ represents the sub-heap of size $2^i$, where each addition is twice the size of the previous.
graph TD A[Heap] B[M] C[S] D[H:Sub Heap] A --> B A --> C A --> D D --> H3 D --> H4 D --> H5 D --> Hi
| |
Memory Sub-Heap Pool
We’ve designed a memory resource pool. This pool consists of numerous allocation segments of fixed size. It means that, regardless of how much space a sub-heap requests, it will request it in units of these fixed-size “segments”. For instance, if the allocation segments in the pool are of size 1MB, then a sub-heap might request space in sizes of 1MB, 2MB, 3MB, etc., rather than requesting non-integer multiples like 1.5MB or 2.5MB.
The dynamic allocation and reclaiming of space by the sub-heaps from a resource pool made up of fixed-size segments provide greater flexibility and may enhance the efficiency of memory utilization.
Types of GC
There are many common types of GC.
In terms of bitmap recorded data, there exists “Generational Garbage Collection”. In Generational Garbage Collection, “generations” or “ages” do not refer to the bitmap. They actually denote portions of the memory used to store objects. Based on the lifespan of objects, GC categorizes them into different generations. The fundamental idea behind this strategy is that newly created objects will become garbage sooner, whereas older objects might live longer.
Generally, in Generational GC, there are two primary generations:
Young Generation: Newly created objects are initially placed here. The Young Generation space is usually smaller and is garbage collected frequently.
Old or Tenured Generation: After objects have lived in the Young Generation for a sufficient amount of time and have survived several garbage collections, they are moved to the Old Generation. The Old Generation space is typically larger than the Young Generation, and garbage collection occurs less frequently since objects in the Old Generation are expected to have a longer lifespan.
Bitmaps serve as a tool here, used to track and manage which objects in each generation are active (i.e., still in use) and which are garbage. When the algorithm extends to Generational GC, multiple bitmaps can be maintained for different generations within the same heap space. In this way, active and inactive objects of each generation can be tracked individually.
“Maintain one bitmap for the Young Generation and another for the Old Generation.” This allows us to consider each generation separately during garbage collection, optimizing the efficiency and performance of the collection process.
In terms of moving existing data, there are “Moving GC” and “Non-Moving GC”. Moving GC relocates living objects to new memory addresses and compresses memory, while Non-Moving GC doesn’t move living objects, allowing other languages to seamlessly call data in memory.
Within this Moving GC category, there are “Generational Copying Collectors” and “Cheney’s Copying Collector”.
Generational Copying Collector: It is a common method of garbage collection, especially in functional programming languages. It assumes that newly created objects will soon become unreachable (i.e., “die”), whereas older objects are more likely to persist. Thus, memory is divided into two or more “generations”. New objects are created in the “Young Generation”, and when they live long enough, they are moved to the “Old Generation”.
Cheney’s Copying Collector: This is a garbage collector used for semi-space. It works by dividing the available memory in half and only allocating objects in one half. When this half is exhausted, the collector performs garbage collection by copying active objects to the other half. The original half is then completely emptied, becoming the new available space. Cheney’s collector is particularly suited for handling data with short lifespans because it quickly copies only the active data while ignoring the dead data. This makes it highly efficient for its “minor collections” (collections that only reclaim Young Generation data) when dealing with programs that handle a large amount of short-lifetime data, such as functional programs. The advantage of this method is that it can efficiently handle memory fragmentation since memory becomes continuously occupied by copying active objects to new locations.
Characteristics:
- Any precise copy gc requires the runtime system to locate and update all pointers of every heap-allocated data.
- In traditional garbage collection strategies (Moving GC), compaction is a commonly used technique, moving active objects into a contiguous region of memory, thereby freeing up unused memory. In other words, it consolidates memory fragmentation.
In Non-Moving GC, there’s “Mark-Sweep”.
The absence of compaction and object movement is very important, as the value of a pointer (i.e., the memory address of an object) remains fixed and there’s no time spent updating moved addresses. This makes Non-Moving GC highly suitable for languages that need to interact with other languages, as they can access objects in memory without the need for extra work. Moreover, the feature of not moving objects is beneficial for supporting multiple native threads. In a multi-threaded environment, if the location of an object in memory keeps shifting, coordination and synchronization between threads become more complicated. Therefore, avoiding object movement simplifies multithreaded programming.
The benefits are as follows:
Lock Simplification: In a multi-threaded environment, if an object needs to be moved (e.g., during the compaction phase of garbage collection), we need to ensure other threads cannot access this object while it’s moving. This might require complex locking strategies and synchronization mechanisms. However, if objects never move, this synchronization need is reduced, making locking strategies simpler.
Pointer Stability: In multi-threaded programs, threads might share pointers or references to objects. If an object moves in memory, all threads sharing that object would need to update their pointers or references. This not only adds synchronization complexity but might also introduce errors, like dangling pointers. If objects don’t move, these pointers remain consistently valid.
Predictability and Performance: Not having to move objects means memory access patterns are more stable and predictable. In multi-threaded programs, predictability is a valuable trait as it can reduce contention between threads, improving overall program performance.
Reduced Pause Times: Object movement in garbage collection can lead to noticeable pauses in an application because all threads must be paused to move objects safely. In a multi-threaded environment, this pause might be more pronounced as more threads might actively use objects. Not moving objects reduces such pauses.
Interoperability with Other Languages or Systems: If your multi-threaded application interoperates with other languages (like C or C++) or systems, having objects in stable locations becomes even more crucial since external code might rely on the fact that objects aren’t moving.
However, Non-Moving GC has its disadvantages:
Memory Fragmentation: Since objects don’t move, spaces in memory might become non-contiguous. This could lead to memory fragmentation, decreasing memory usage efficiency.
Memory Allocation: Due to fragmentation, memory allocation can become more complicated. For instance, if there isn’t enough contiguous space to meet an allocation request, the allocator might need to do more work to find available space. This might decrease allocation performance.
Memory Usage: Due to fragmentation, memory usage can become less efficient. For instance, if there’s a large object without enough contiguous space to store it, it might get split into multiple fragments which could be assigned to different contiguous spaces, potentially decreasing memory utilization.
Memory Overhead: Due to fragmentation, memory overhead can become less efficient. For instance, if there’s a large object without enough contiguous space to store it, it might get split into multiple fragments which could be assigned to different contiguous spaces, potentially decreasing memory utilization.
……
To address these problems requires many complicated steps, which won’t be elaborated on here. We’ll focus on Bog’s GC for the explanation.
Meta Bitmap
“Meta Bitmap” or “meta-level bitmaps”. This is a higher-level bitmap that summarizes the contents of the original bitmap. This hierarchical structure is similar to the inode mapping in file systems or the use of multi-level page tables in computer memory management.
For instance, consider a simple bitmap: 1100 1100. A meta-level bitmap might represent how many free blocks are in every 4 bits. In this scenario, the meta-level bitmap could be 1021 (indicating there’s 1 free block in the first 4 bits, 2 free blocks in the second 4 bits, and so on).
The system doesn’t just blindly start searching from the beginning of the bitmap for a free bit; it remembers the last-found position. This way, the next search can begin from this position, speeding up the search process further. This means that the time needed to find the next free bit remains approximately the same, regardless of memory size, which is a very efficient performance characteristic.
What about the worst-case scenario?
Let’s design for a 32-bit architecture. A 32-bit architecture means that the computer’s instruction set and data path are designed to handle data units 32 bits wide. Therefore, when operating on 32-bit data units (like an integer or part of a bitmap), such an architecture can typically process all 32 bits at once. This results in logarithmic operations based on 32, because for larger data sections (like a bitmap), operations might need to proceed in blocks/chunks of 32 bits. The search time is logarithmically related to the size of segmentSize.
For example, if a bitmap is 320 bits long, then on a 32-bit architecture, the worst-case scenario might require checking 10 blocks of 32 bits to find a free bit. This can be represented by log32(320), which results in 10.
Bitmap
Since Bog’s GC is essentially still based on “Mark-Sweep”, using bitmaps to record data is indispensable. In Bog, we adopted the method of “bitmap records data” for GC. And to improve efficiency, we introduced the concept of meta-bitmaps, where every 4 elements correspond to a meta-bitmap, recording the occupancy status of multiple spaces, and increasing the depth based on the object age in the heap.
Implementation
In reality, Bog’s design is a bit more complex. Here are sample in practical code:
| |
max_size: Represents the maximum number of bytes a Page can store. We have defined a constant to represent the size of 1 MiB and ensure at compile time that the size of the Page type is exactly 1 MiB. Otherwise, a compile-time error will be triggered.val_count: Represents the number of Value objects a Page can store.pad_size: Represents the size of the unused space remaining in the Page after storing the maximum number of Value objects.
| |
- An enumeration type named
Stateis defined, which has four possible values: empty, white, gray, and black.- In the context of Garbage Collection (GC), these states are typically related to the status of objects during the GC process. For instance, in generational garbage collection, an object might be marked as “white” (unvisited/pending), “gray” (visited but its references not yet processed), or “black” (processed).
List: Stores pointers of the Page type.meta: Represents the state of each Value object within a Page. Here, we use an enum type to represent the state, and since there are only 4 states, they can be represented using 2 bits. Thus, we can use a u32 to represent the state of all Value objects within a Page. Each State potentially corresponds to the status of a Value object in thevaluesfield.- A
__paddingfield, used to pad extra memory space. Its size is determined by the previously mentionedpad_sizeand is an array of bytes (u8). This is commonly used to ensure memory alignment of data structures. free: Represents the number, index, or other information related to free or available spaces concerning memory management.marked: Represents the number, index, or other information about marked spaces, used during the garbage collection process to determine whether to continue checking values on this page.values: Represents the Value objects in a Page. It’s an array of Value objects, the size of which is determined byval_count.
Bog GC 设计 -- 概念篇
Bog 是一款基于 Zig 开发的小型脚本语言。它的 GC 设计受到一篇论文An efficient of Non-Moving GC for Function languages的启发。
梗概
- 概述
- Heap 的设计
- GC 的类别
- Bitmap 的设计
- 实现
概述
GC 是一种垃圾回收的机制,主要是针对heap区域的内存管理策略。在堆中的内存分配是按照指数级增长的大小进行的,此外还有一个专门用于非常大对象的特殊子堆。这种方法的一个优点可能是它可以高效地处理各种大小的内存请求。
以公式来进行表示:
$$ Heap = (M, S, (H_3, H_4, …, H_{12})) $$
其中:
- M 是特殊的区域,用于存储大对象
- S 是空闲区域
- H 是子堆,用于存储小对象,$H_i$表示大小为$2^i$的子堆,每次新增都为之前的两倍
graph TD A[Heap] B[M] C[S] D[H:Sub Heap] A --> B A --> C A --> D D --> H3 D --> H4 D --> H5 D --> Hi
| |
内存子堆池
我们设计一个内存的资源池。这个池由许多固定大小的分配段组成。这意味着,无论子堆请求多少空间,它都会以这些固定大小的“段”为单位来请求。例如,如果池中的分配段大小为 1MB,那么一个子堆可能会请求 1MB、2MB、3MB 等大小的空间,而不是请求 1.5MB 或 2.5MB 这样的非整数倍的大小。
而子堆从一个由固定大小的段组成的资源池中动态分配和回收空间,这种策略可以提供更高的灵活性,并可能提高内存使用的效率。
GC 的类别
常见的 GC 有很多类型。
以位图记录数据来说,有“代际垃圾收集 GC”。在代际垃圾收集(Generational Garbage Collection)中,“代"或"世代"并不是指位图。它们实际上是指内存中的一部分,用于存储对象。基于对象的生存周期,GC 把它们分为不同的代。这种策略背后的基本思想是,新创建的对象很快就会变为垃圾,而旧对象则可能存活得更久。
一般来说,在代际 GC 中,有两个主要的代:
新生代(Young Generation):新创建的对象首先被放置在这里。新生代空间通常较小,并且经常进行垃圾收集。
老年代(Old or Tenured Generation):当对象在新生代中存活了足够长的时间并经历了多次垃圾收集后,它们会被移动到老年代。老年代空间通常比新生代大,并且垃圾收集的频率较低,因为预期老年代中的对象会有更长的生命周期。
位图在这里是一个工具,用于跟踪和管理每一代中哪些对象是活跃的(即仍在使用中)和哪些是垃圾。当算法扩展为代际 GC 时,可以为同一个堆空间的不同代维护多个位图。这样,每个代的活动和非活动对象都可以被单独地跟踪。
“为新生代维护一个位图,为老年代维护另一个位图”。这使得在进行垃圾收集时,我们可以单独地考虑每一个代,从而优化垃圾收集的效率和性能。
以是否移动旧有的数据来说,有“移动 GC”和“非移动 GC”。移动 GC 会将存活的对象移动到新的内存地址、压缩内存,而非移动 GC 则不会移动存活的对象,可以无缝由其他语言来调用内存里的数据。
在这种移动 GC 中,有“分代复制收集器”和“Cheney 复制收集器”。
分代复制收集器(Generational Copying Collector): 是垃圾收集的一种常见方法,特别是在函数式编程语言中。它假设新创建的对象很快就会变得不可达(即“死亡”),而老的对象则更可能持续存在。因此,内存被分成两个或更多的“代”,新对象在“新生代”中创建,当它们存活足够长的时间时,它们会被移到“老生代”。
Cheney 的拷贝收集器: 是一种用于半区(semi-space)的拷贝垃圾收集器。它的工作原理是将可用内存分为两半,并且只在其中一半中分配对象。当这一半用完时,收集器通过拷贝活跃对象到另一半空间来进行垃圾收集。然后,原先的那一半空间就完全清空,成为新的可用空间。Cheney 的收集器特别适用于处理短生命周期的数据,因为它可以快速地只拷贝活跃的数据,而忽略死亡的数据。这使得它在处理大量短生命周期数据的程序(例如函数式程序)时,对于其“次要收集”(minor collection,即仅仅回收新生代数据的收集)非常高效。这种方法的优势在于它可以有效地处理内存碎片,因为通过复制活动对象到新位置,内存会被连续地占用。
特点:
- 任何精确的 copy gc 都需要 runtime 系统定位和更新每个堆分配数据的所有指针
- 在传统的垃圾收集策略(移动 GC)中,压缩是一种常用的技术,它会将活跃的对象移到内存的一个连续区域中,从而释放出未使用的内存。换言之,就是整理内存碎片。
在非移动 GC 中,有“标记-清除”。
不需要进行压缩和对象移动这一特性是非常重要,指针的值(即对象的内存地址)是固定的,也不需要花时间更新移动的地址。这使得非移动 GC 非常适合于需要与其他语言进行交互的语言,因为它们可以在不需要额外的工作的情况下访问内存中的对象。而且不需要移动对象的这一特性对于支持多原生线程也是有益的。在多线程环境中,如果对象在内存中的位置不断移动,那么线程之间的协调和同步将变得更加复杂。因此,避免对象移动可以简化多线程编程。
有益的原因如下:
锁的简化: 在一个多线程环境中,如果对象需要移动(例如,在垃圾收集的压缩阶段),那么我们需要确保其他线程在对象移动时不能访问这个对象。这可能需要使用复杂的锁策略和同步机制。但是,如果对象永远不移动,我们就可以减少这种同步的需求,使得锁策略更简单。
指针的稳定性: 在多线程程序中,线程之间可能会共享指向对象的指针或引用。如果对象在内存中移动了,那么所有共享该对象的线程都需要更新其指针或引用。这不仅会增加同步的复杂性,而且可能会引入错误,如野指针。如果对象不移动,这些指针就会始终有效。
预测性和性能: 不需要移动对象意味着内存访问模式更加稳定和可预测。在多线程程序中,预测性是一个宝贵的特性,因为它可以减少线程之间的争用,从而提高程序的整体性能。
减少暂停时间: 垃圾收集中的对象移动可能导致应用程序的明显暂停,因为必须暂停所有线程来安全地进行移动。在多线程环境中,这种暂停可能更加明显,因为有更多的线程可能正在活跃地使用对象。不移动对象可以减少这种暂停。
与其他语言或系统的互操作: 如果您的多线程应用程序与其他语言(如 C 或 C++)或系统进行互操作,那么对象的稳定位置将更加重要,因为外部代码可能依赖于对象不移动的事实。
但同样的,非移动 GC 也有缺点:
- 内存碎片: 由于对象不会移动,因此内存中的空间可能会变得不连续。这可能会导致内存碎片,从而降低内存使用效率。
- 内存分配: 由于内存碎片,内存分配可能会变得更加复杂。例如,如果没有足够的连续空间来满足分配请求,那么分配器可能需要进行更多的工作来查找可用的空间。这可能会导致分配的性能下降。
- 内存使用: 由于内存碎片,内存使用可能会变得更加低效。例如,如果有一个大对象,但是没有足够的连续空间来存储它,那么它可能会被分成多个碎片,这些碎片可能会被分配给不同的连续空间。这可能会导致内存使用率降低。
- 内存占用: 由于内存碎片,内存占用可能会变得更加低效。例如,如果有一个大对象,但是没有足够的连续空间来存储它,那么它可能会被分成多个碎片,这些碎片可能会被分配给不同的连续空间。这可能会导致内存使用率降低。
为了解决这些问题需要很多复杂的步骤,在此不多赘述。单以 Bog 的 GC 来讲解。
Meta Bitmap
“元级位图”或“meta-level bitmaps”。这是一个更高级别的位图,用于汇总原始位图的内容。这种层次化的结构类似于文件系统中的 inode 映射或多级页表在计算机内存管理中的使用。
例如,考虑一个简单的位图:1100 1100。一个元级位图可能表示每 4 位中有多少个空闲块。在这种情况下,元级位图可能是 1021(表示第一个 4 位中有 1 个空闲块,第二个 4 位中有 2 个空闲块,以此类推)。
系统不仅仅是盲目地从位图的开始处查找空闲位,而是记住上一次查找到的位置。这样,下次查找可以从这个位置开始,进一步加速查找过程。这意味着无论内存大小如何,找到下一个空闲位所需的时间都大致相同,这是一个非常高效的性能特性。
如果是最坏的情况呢?
以 32 位架构来设计。32 位架构意味着计算机的指令集和数据路径设计为处理 32 位宽的数据单元。因此,当操作 32 位数据单元(例如一个整数或位图的一部分)时,这样的架构通常可以一次性处理所有 32 位。这导致以 32 为底的对数操作,因为对于较大的数据段(如一个位图),操作可能需要按 32 位的块/段进行。查找时间与 segmentSize 的大小成对数关系。
例如,如果一个位图有 320 位,那么在 32 位架构上,最坏的情况可能需要检查 10 个 32 位块才能找到一个空闲位。这可以通过 $\log_{32}(320)$来表示,结果是 10。
Bitmap
由于 Bog 的 GC 本质上还是采用了“标记-清除”,所以利用位图来记录数据是必不可少的。在 Bog 中,我们采用了“位图记录数据”的方式来进行 GC。而为了提高效率,我们增加了元位图的概念,即每 4 个元素对应一个元位图,用于记录多空间的占用状态,并且根据 heap 的对象时间增加深度。
实现
实际上,在 Bog 的设计中,要更加复杂一些。我们增加了
| |
max_size: 表示一个 Page 能够存储的最大字节数。我们定义了一个常量来表示 1 MiB 的大小,并在编译时确保 Page 类型的大小恰好为 1 MiB。否则将会触发编译时错误。val_count: 表示一个 Page 能够存储的 Value 对象的数量pad_size: 表示在存储了最大数量的 Value 对象后,Page 剩余的未使用的空间大小
| |
- 定义了一个名为 State 的枚举类型,它有四个可能的值:empty、white、gray 和 black。
- 在垃圾收集(GC)的上下文中,这些状态通常与对象在 GC 过程中的状态有关。例如,在分代垃圾收集中,对象可能会被标记为 “white”(未访问/待处理),“gray”(已访问但其引用尚未处理)或 “black”(已处理)。
List: 存储 Page 类型的指针meta: 表示一个 Page 中每个 Value 对象的状态。这里我们使用了一个枚举类型来表示状态,因为状态只有 4 种,所以可以用 2 位来表示。因此,我们可以使用一个 u32 来表示一个 Page 中所有 Value 对象的状态。这样,我们就可以使用一个 u32 来表示一个 Page 中所有 Value 对象的状态。每一个 State 可能对应一个在 values 字段中的 Value 对象的状态。__padding的字段,用于填充额外的内存空间。它的大小由之前提到的 pad_size 决定,且是一个字节(u8)数组。这通常用于确保数据结构的内存对齐。free: 表示空闲或可用的空间数量、索引或其他与内存管理相关的信息marked: 表示已标记的空间数量、索引或其他与内存管理相关的信息,在垃圾收集的过程中用于检测是否应继续在此页面中检查值values: 表示一个 Page 中的 Value 对象。它是一个 Value 对象的数组,其大小由 val_count 决定。
欢迎 Zig 爱好者向本网站供稿
欢迎社区用户向 ZigCC 供稿(关于 Zig 的任何话题),方便与社区更多人分享。文章会发布在:
{kind=link}
供稿方式
- Fork 仓库 https://github.com/zigcc/zigcc.github.io
- 在
content/post内添加自己的文章(md 或 org 格式均可),文件命名为:${YYYY}-${MM}-${DD}-${SLUG}.md - 文件开始需要包含一些描述信息,例如本文件中的:
| |
本地预览
在写完文章后,可以使用 Hugo 进行本地预览,只需在项目根目录执行 hugo server,这会启动一个 HTTP 服务,默认的访问地址是: http://localhost:1313/